Potřebujete-li do jedné shopitem v Mergadu připojit doplňková data z externích feedů, použijete pravidlo datového importu. Pravidlo datového importu podporuje feedy ve formátu CSV. Občas přicházejí poptávky, zda bychom mohli toto pravidlo naučit i různé formáty XML feedů. To by bylo hodně pracné. CSV feed je totiž docela jednoduchý - jedna shopitem je jeden řádek a názvy elementů jsou uvedeny na prvním řádku. Naproti tomu podpora XML by vyžadovala definovat různé formáty, jejich kořenové i běžné elementy, postavit funkce nad těmito elementy… Zkrátka by to bylo dosti pracné a stejně by musel uživatel definovat chování jednotlivých elementů. De facto by práce byla podobná úpravě XML feedu na CSV feed.
Jak převést XML feed na CSV feed
Než se pustím do porovnání dvou možností, jak si data připravit, řeknu co vlastně příprava dat v mých očích obnáší. Dříve jsem razil názor, že čím více dat tím lépe. Dnes si to nemyslím. Člověk by měl mít k dispozici právě ta data, která potřebuje. Neměla by chybět. Ale ani by jich mělo být extra navíc. To pak způsobuje nepřehlednost, více chyb, roste náročnost zpracování…
V přípravě dat tedy budeme potřebovat:
- převést XML formát na CSV
- do CSV zapsat pouze data, která budeme potřebovat (ostatní vynechat resp. skrýt)
 Varianta 1: Mergado
Varianta 1: Mergado
Máme dvě možnosti. První je použít Mergado a klasickým způsobem nastavit vstupní formát (k dispozici máme jak známé formáty tak vlastní custom formát) a výstup stanovit do CSV. V Mergadu pak lze editovat hodnoty elementů, skrývat elementy, zkrátka zpracovat data obvyklým způsobem.
![]() Výhody:
Výhody:
- intuitivní práce
- široké možnosti Mergada
![]() Nevýhody:
Nevýhody:
- některé formáty Mergado zpracovat nedokáže (zatím)
- delší interval zpracování
 Varianta 2: Blending Bull
Varianta 2: Blending Bull
Druhou možností je Blending Bull. Uvedu příklad postupu. Cílem nebude postup 100% objímající všechny možné kombinace vstupních dat, ale návod, jak můžete přemýšlet nad zpracováním Vašich unikátních dat. Jako příklad si vezmu specifický Heureka dostupnostní XML feedu. V praxi může jít o různé formáty dat od dodavatelů, ze skladových systémů aj.
Krok 0: Jak vypadají vstupní data
Do aplikace Blending Bull jsem napojil datový zdroj. Nastavením v průvodci tvorbou nového souboru jsem odstranil hlavičku XML souboru a zbyly jednotlivé items. Ty vypadají např. takhle. Všimněte si, že item je na více řádcích, na začátcích řádků obsahuje bílé znaky. Obsahuje zanořené elementy i elementy s parametry.
<item id="54">
<stock_quantity>45</stock_quantity>
<delivery_time orderDeadline="2011-09-10 12:00">2011-09-11 13:00</delivery_time>
<depot id="434">
<stock_quantity>2</stock_quantity>
</depot>
<depot id="437">
<pickup_time orderDeadline="2011-09-10 12:00">2011-09-11 18:00</pickup_time>
</depot>
</item>
Krok 1: Naformátovat do tabulky
O tomhle pravidle jsem psal podrobnější návod. Výstupem bude jedna item na jednom řádku. S ní se nám bude dále lépe pracovat.
<item id="54"><stock_quantity>45</stock_quantity><delivery_time orderDeadline="2011-09-10 12:00">2011-09-11 13:00</delivery_time><depot id="434"><stock_quantity>2</stock_quantity></depot><depot id="437"><pickup_time orderDeadline="2011-09-10 12:00">2011-09-11 18:00</pickup_time></depot></item>
Krok 2: Pořadí elementů
Kdybychom měli jistotu, že pořadí elementů bude vždy a u všech items stejné, můžeme tento krok vynechat. V praxi v případě XML však nemusí být jisté jednak to, že všechny items jednoho XML souboru mají elementy ve stejném pořadí, jednak že při různých zpracováních v čase jednoho souboru nemusí být pořadí items vždy stejné. Abych se vyvaroval problémů spojených s různým pořadím elementů, definuji pořadí elementů. Podrobně jsem o tom psal v tomto návodu.
V našem případě mi budou stačit sloupce id (resp. na výstupu ITEM_ID) a STOCK_QUANTITY. ID je parametrem elementu item, tedy bude vždy na začátku dané item. Jedním pravidlem tedy definuji pořadí elementu stock_quantity. Obdobnými pravidly bych mohl definovat pořadí dalších elementů, viz. návod pod odkazem výše.
Pravidlo:
Nalézt v datovém zdroji text:
<item>(.*)<stock_quantity>(.*)<\/stock_quantity>(.*)<\/item>
Nahradit za text:<item><stock_quantity>\g<2></stock_quantity>\g<1>\g<3></item>
Zpracovat jako regulární výraz: ANO
Výstup bude vypadat takto. Všimněte si, že element stock_quantity se posunul hned za úvodní element item.
<item id="54"><stock_quantity>45</stock_quantity><delivery_time orderDeadline="2011-09-10 12:00">2011-09-11 13:00</delivery_time><depot id="434"><stock_quantity>2</stock_quantity></depot><depot id="437"><pickup_time orderDeadline="2011-09-10 12:00">2011-09-11 18:00</pickup_time></depot></item>
Krok 3: Uložit hodnoty z XML formátu do CSV formátu
Nyní již máme pevně definované umístění elementů, které nás v XML feedu zajímají. Je tedy možné regulárním výrazem určit proměnné, které uložíme do výstupního CSV souboru. Zbytek se do výstupu nepropíše, a tak ho ani nemusíme mazat. Nás v našem příkladě zajímaly pouze dvě proměnné. Obdobně byste definovali další proměnné, pokud byste jich do výstupu chtěli uložit více.
Nalézt v datovém zdroji text:
<item id="(.*?)"><stock_quantity>(.*?)<\/stock_quantity>.*<\/item>
Nahradit za text:"\g<1>","\g<2>"
Zpracovat jako regulární výraz: ANO
Výstup bude vypadat takto. Mohli bychom ho definovat i bez uvozovek, s jiným oddělovačem než je čárka aj. Je to de facto řádek CSV.
"54","45"
Krok 4: Hlavička CSV souboru
Nyní nám zbývá na začátek souboru vložit hlavičku. Pravidlem Vložit text na začátek souboru vložíme hodnotu:
"ITEM_ID","STOCK_QUANTITY"
Pozor, jsou to dva řádky - na prvním je text, na druhém prázdný řádek (klávesa enter). Tím do CSV doplníme hlavičku a máme hotovo. Pravidla v Blending Bullovi budou vypadat takhle. Náhled výstupních dat vidíte na screenshotu vpravo.
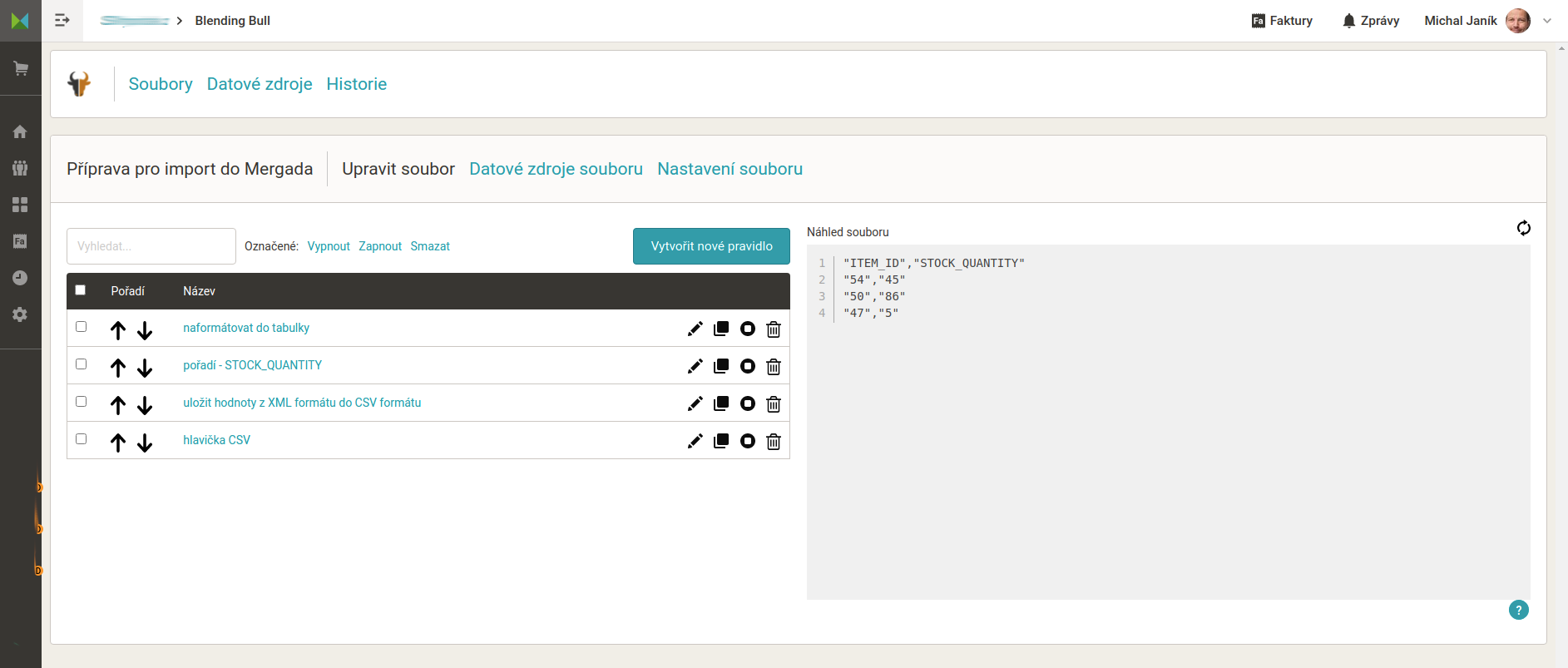
Porovnání s využitím Mergada vychází de facto opačně než první pracovní postup viz výše:
![]() Výhody:
Výhody:
- zpracuje i formáty které Mergado (zatím) neumí
- rychlejší aktualizace dat
![]() Nevýhody:
Nevýhody:
- méně intuitivní ovládání aplikace, hodí se základní znalosti práce s feedy
- chybí pokročilé možnosti Mergada
Ač se uvedený postup může zdát složitý, jde o čtyři pravidla z nichž první a poslední jsou jednoduchá. Výhodou použití Blending Bulla jsou široké možnosti a obecnost. Dokáže zpracovat téměř jakýkoliv XML feed tak, aby se dal do Megrada pravidlem datového importu nahrát ![]()