Tuhle padla otázka, zda lze “připojit” informace z Heureka dostupnostního XML feedu k produktům v exportu v Mergadu. Dříve jsem říkával, že nikoliv, protože pravidlo datového importu podporuje napojení dat z formátu CSV. Opak je ovšem pravdou. Lze to nastavit a zabere to sotva pár minut.
Postup v kostce
Využijeme pravidlo datového importu. Abychom ze vstupního dostupnostního XML feedu vytvořili CSV s potřebnými daty, použijeme aplikaci Blending Bull.
O aplikaci Blending Bull
Blending Bull je známý jako aplikace pro spojování datových feedů. Obsahuje ovšem také datový editor. Ten data nenačítá do databáze, ale upravuje rovnu text v souboru. Díky tomu dokáže zpracovat i dostupnostní XML feed nebo různé další formáty CSV či XML feedů!
Pracovní postup
- Jako datový zdroj v aplikaci Blending Bull (vstupní feed) vložíme URL dostupnostního XML feedu. Odtud bude Bull data brát a pravidelně je aktualizovat.
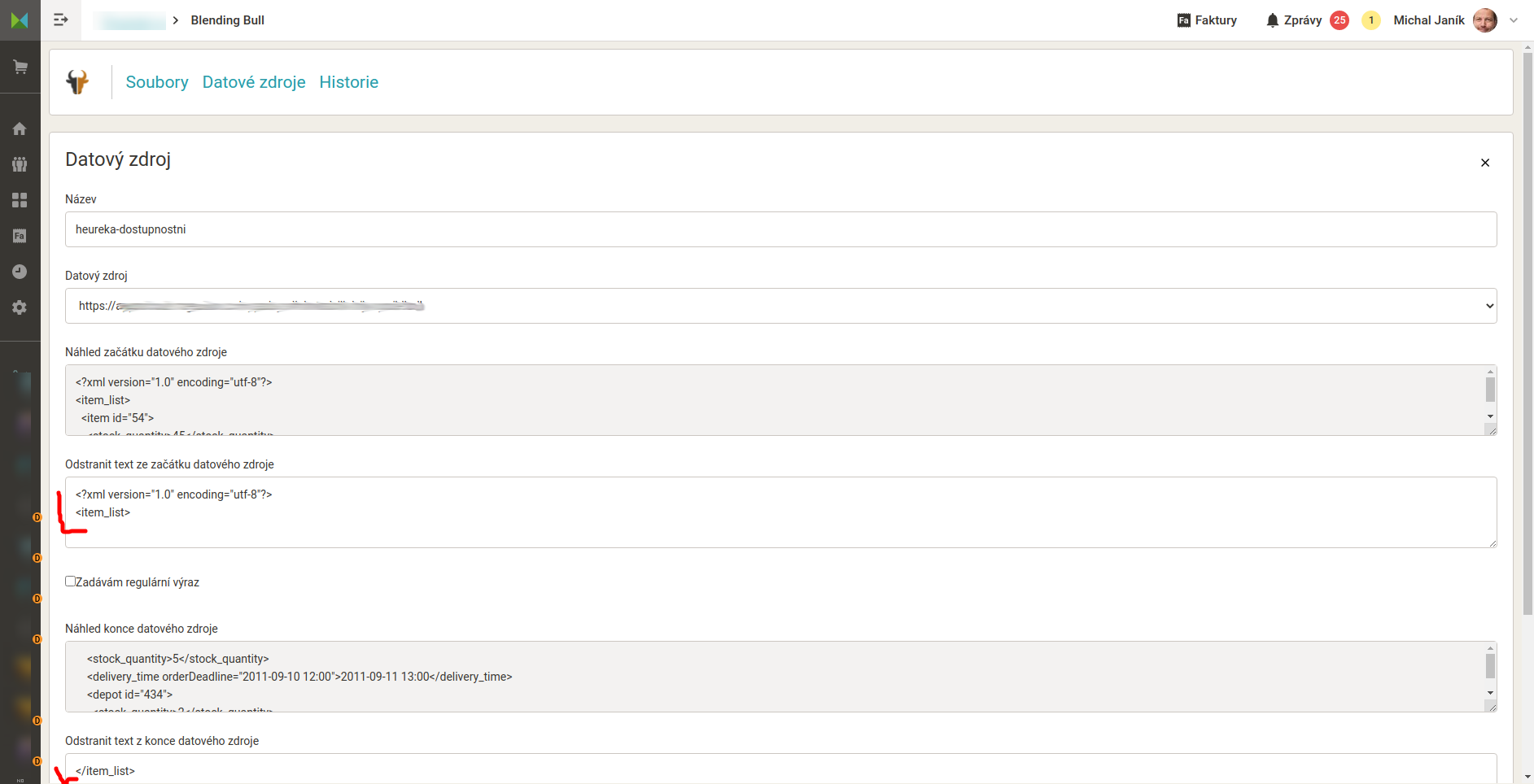
- Vytvoříme nový výstupní soubor. Do něj jako zdroj dat napojíme dostupnostní feed. V nastavení datového zdroje nastavíme smazání hlavičky a patičky XML tak, aby obsah souboru začínal
<item...a končil</item>.
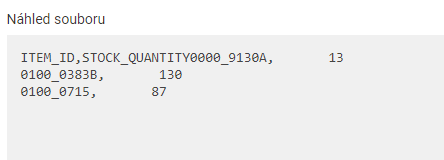
- Pomocí pravidel upravíme obsah souboru. Já se domníval, že jediným pravidlem s regulárním výrazem dokáži data z dostupnostního XML feedu vyparsovat a uložit do struktury CSV souboru. Zápis mne ale zlobil, a tak jsem postup rozdělil na více jednodušších pravidel. Většinou šlo o pravidla “Najít a nahradit” s tím, že se nahrazovalo za prázdný obsah, tedy byl text odstraněn. Uvedu příklad pravidel. Vy si vytvoříte pravidla vlastní dle charakteru vašich dat.
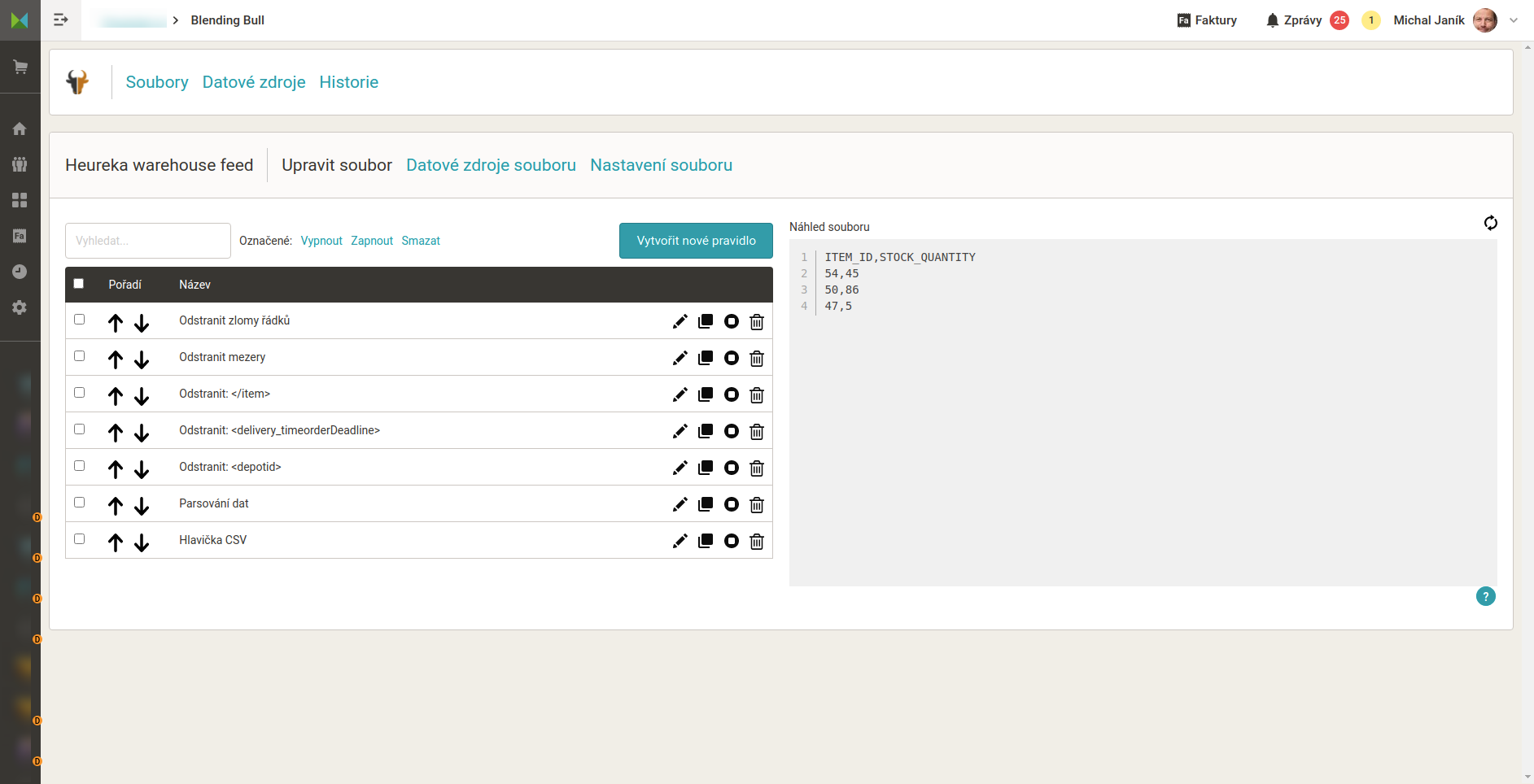
Tabulka s popisem pravidel
| Pravidlo | Nalézt v datovém zdroji text | Nahradit za text | Regulární výraz? | Poznámka |
|---|---|---|---|---|
| Odstranit zlomy řádků | \n |
nic | ano | |
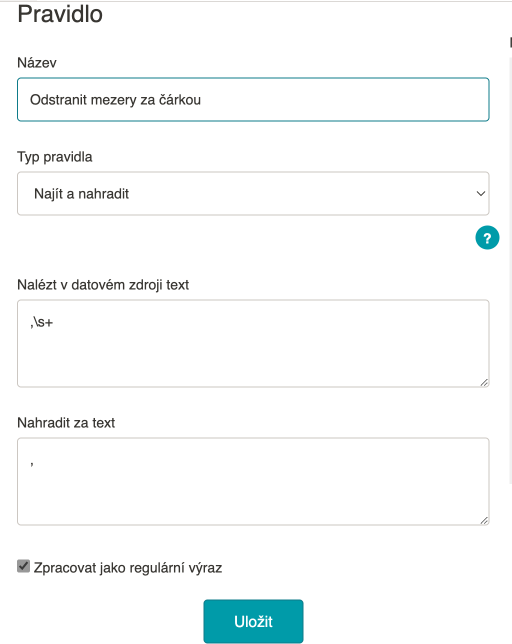
| Odstranit mezery | (mezera) | nic | - | |
| Odstranit: /item | </item> |
nový řádek (enter) | - | |
| Odstranit: delivery… | <delivery_timeorderDeadline.*<\/delivery_time> |
nic | ano | |
| Odstranit: depotid | <depotid.*<\/depot> |
nic | ano | |
| Parsování dat | <itemid="(.*)"><stock_quantity>(.*)<\/stock_quantity> |
\g<1>,\g<2> |
ano | |
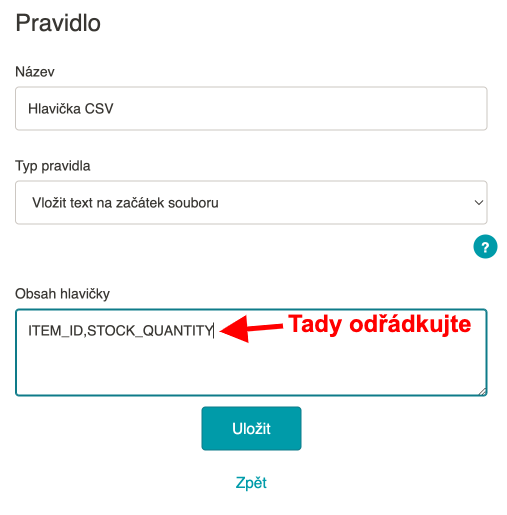
| Hlavička CSV | typ pravidla Vložit na začátek souboru | ITEM_ID,STOCK_QUANTITY(enter) |
- |
Zápis pravidel je ilustrační. V mém případě fungoval. Ve vašem případě může být potřeba pravidla upravit dle situace. Některá pravidla nemusí být potřeba vůbec. Cílem bylo ukázat princip.
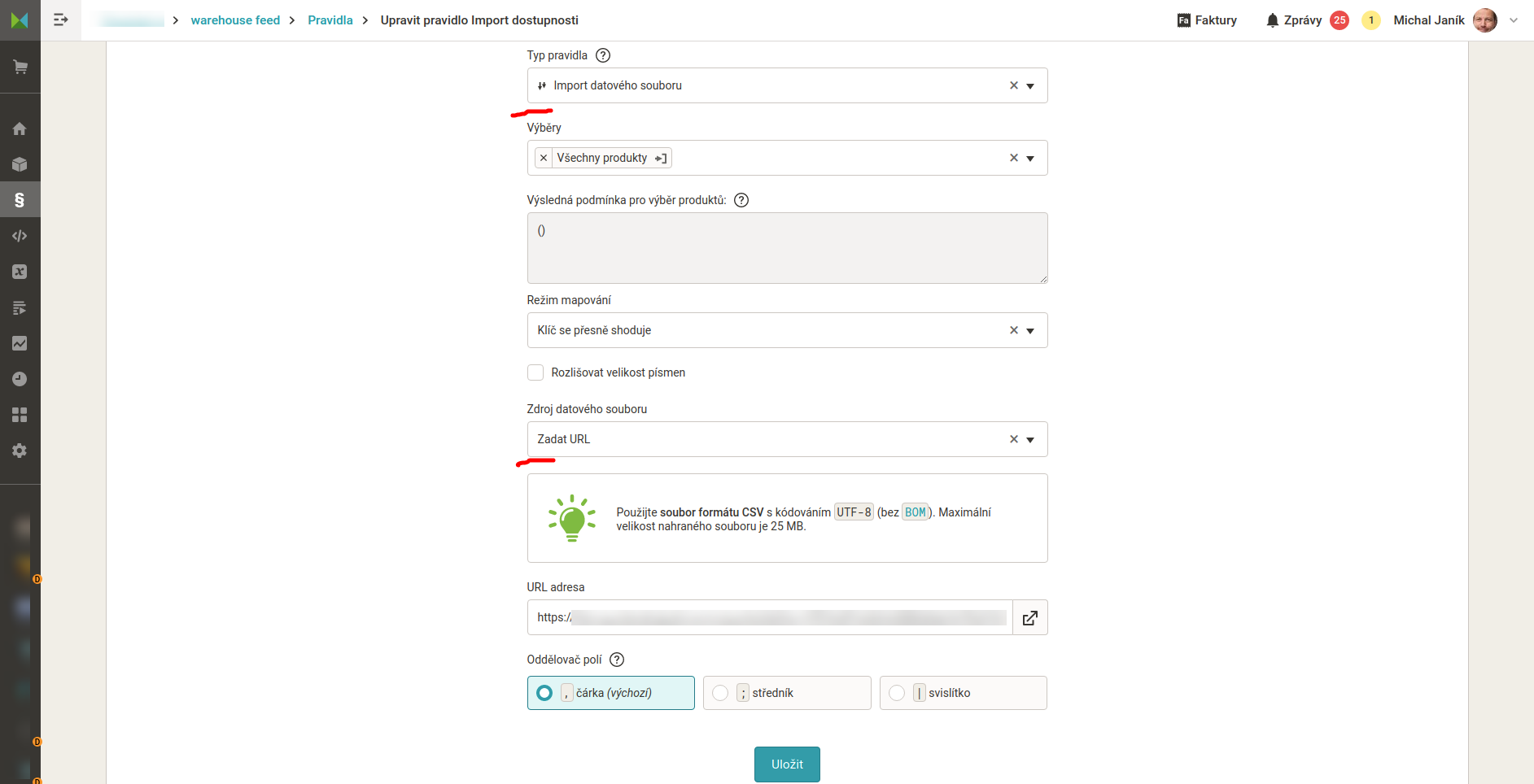
- Výstupní soubor z aplikace Blending Bull načteme pomocí pravidla datového importu do exportu v Mergadu.
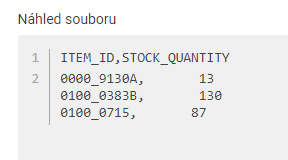
- A máme hotovo. Výsledek může v Mergadu vypadat podobně viz. příklad. Data můžeme využít pro řízení kampaní, výběry, přípravu dat pro marketplaces aj.
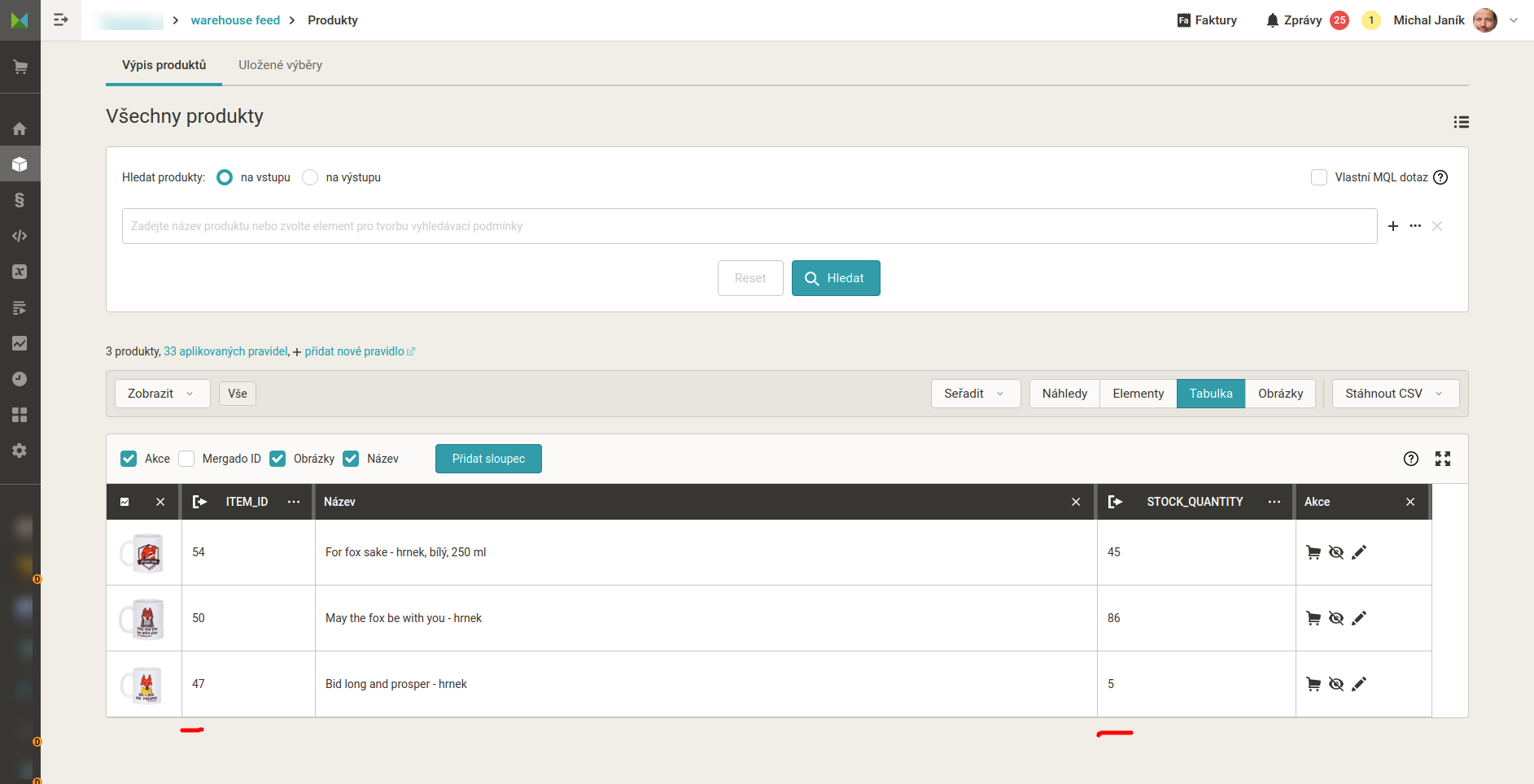
Přestože popis postupu zabral hodně řádků, naklikat jej dokážete za pár minut.
Podobně lze zpracovat i jiné formáty
V tomto příkladě jsou na vstupu data ve formátu Heureka dostupnostní feed. Obdobně můžete zpracovat jiné formáty XML případně CSV feedů. Pomocí aplikace Blending Bull je převedete do CSV (případně XML), které pak napojíte do Mergada pravidlem datového importu, nebo zpracujete jiným způsobem.
Poznámka o screenshotu Blending Bull
Uvedený screenshot je z vývojové verze aplikace, kterou připravujeme. Na produkci by měla být v řádu jednotek týdnů. Již nyní můžete s Bullem pracovat stejně. Pouze jsou pravidla v rozhraní aplikace v části Vstupní soubory → detail souboru → Pravidla
Zlobily mne konce řádků. Tedy jsem je odstranil. Výstupem je jeden dlouhý řádek. ↩︎
Zlobily mne mezery na různých místech XML. Odstranil jsem je. ↩︎
Položka item ukončuje položku zboží. Nám odřádkuje CSV kde jeden řádek bude jedna shopitem. Nahradíme ji tedy za nový řádek (stisk enter). ↩︎
Jádro celého zpracování. Z položek
(.*)načte pravidlo data. Skupin dat může být více. Do výstupu je vložíme zápisem\g<1>,\g<2>atp. kde číslo udává pořadí skupiny v parsování. Já jsem jako oddělovač zvolil čárku. ↩︎