Naváži na včerejší povídání o tom, jak z produktového feedu vytvořit dostupnostní feed. Dnes se podívám na to, jak pomocí aplikace Blending Bull zapsat data do souboru ve formátu Heureka dostupnostního XML. Na dva díly jsem povídání rozdělil proto, že jedna část situace je data získat, druhá část získaná data zapsat do potřebného tvaru. A každou z nich lze řešit více způsoby.
Získání dat pro dostupnostní feed
Včera jsem popsal, jak dostupnostní feed vytvořit z produktového feedu. Na vstupu byl produktový feed ve formátu Mergado Product, nicméně mohl by tam být formát Heureka.cz, Google Shopping a jiné. Získat data lze i jinými způsoby. Např. mohou být generována přímo shopsystémem do zvláštních elementů. Mohou být jako doplňkový CSV feed ze skladového systému aj. Následující postup lze využít jako inspiraci pro zpracování různých dat.
Vstupní data
Pro náš příklad máme na vstupu feed - zde mu budeme říkat datový zdroj - ve formátu viz. příklad.
<SHOPITEM>
<ITEM_ID>54</ITEM_ID>
<DELIVERY_TERM_ORDER>2021-12-21 12:00</DELIVERY_TERM_ORDER>
<DELIVERY_TERM_GET>2021-12-23 12:00</DELIVERY_TERM_GET>
<STOCK_QUANTITY>5</STOCK_QUANTITY>
</SHOPITEM>
kde:
ITEM_IDje unikátní identifikátor položky zboží, odpovídá identifikátoru z produktového feeduDELIVERY_TERM_ORDERje termín pro přijetí objednávkyDELIVERY_TERM_GETje termín doručení objednávky přijaté před termínem viz. předchozí bodSTOCK_QUANTITYje počet kusů zboží skladem. Tento element v příkladu na začátku příspěvku nebyl. Přidal jsem si ho běžným postupem v Mergadu (vytvořit element, naplnit hodnoty pravidlem nebo ručně).
Zpracování dat
Použijeme postupy již známé z jiných příkladů. Odkáži se tedy na ně a podrobněji vysvětlím samotné získání a uložení dat. Seznam všech pravidel vypadal v Blending Bullovi takto.
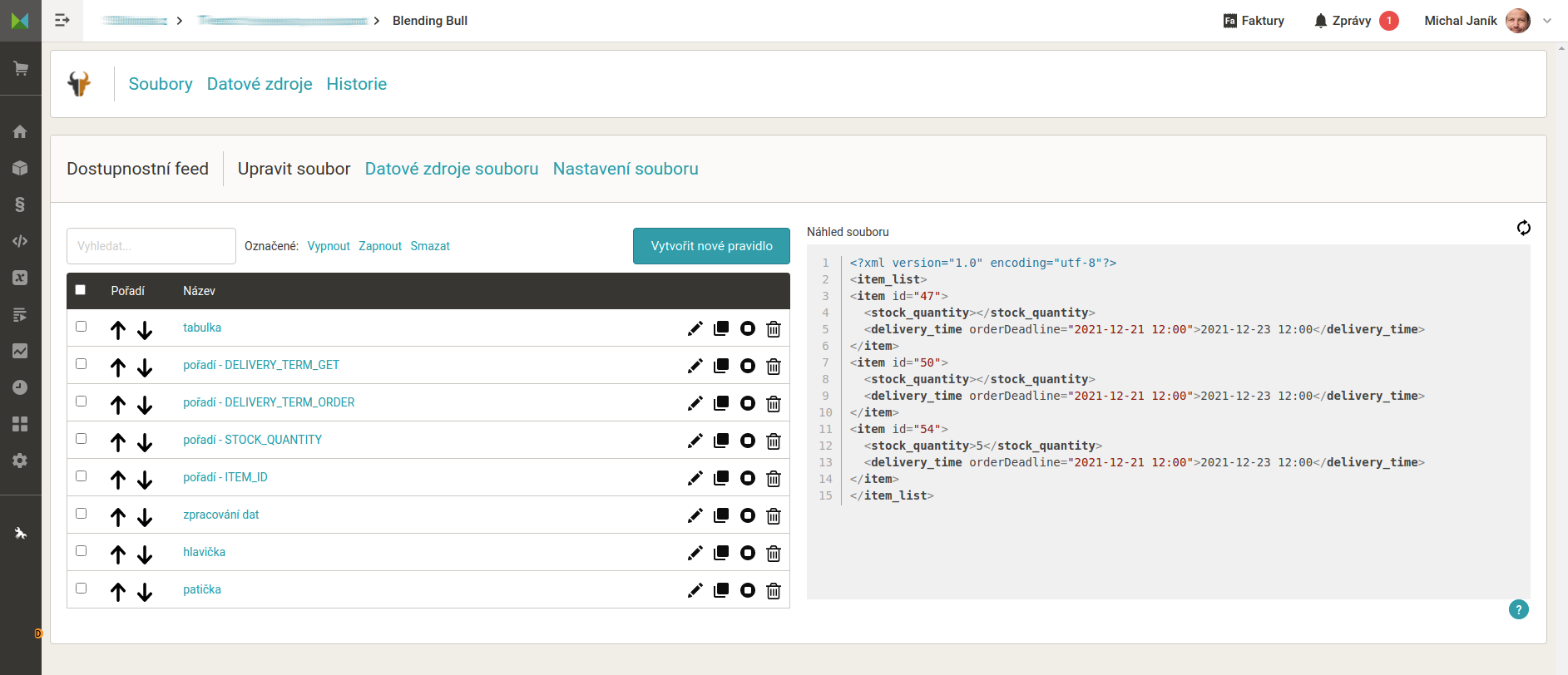
Náhled pravidel v appce Blending Bull. Některé položky mají element stock_quantity prázdný záměrně. Testoval jsem odolnost zpracování, zda absence elementu zpracování nerozbije.
Pracovní postup
- Převedeme data pravidlem do tabulky.
- Stanovíme pořadí elementů. Cílem je pořadí: ITEM_ID, STOCK_QUANTITY, DELIVERY_TERM_ORDER, DELIVERY_TERM_GET. Vy můžete mít elementy i pořadí jiné. Podstatné je, že máme jistotu, v jakém pořadí dále elementy budou.
- Zpracování dat - viz. níže
- Doplníme hlavičku. V našem případě toto, včetně prázdného řádku.
Text hlavičky
<?xml version="1.0" encoding="utf-8"?>
<item_list>
- Doplníme patičku
Text patičky
</item_list>
Zpracování dat
Jde de facto o jediné pravidlo Najít a nahradit.
- Typ pravidla: Najít a nahradit
- Nalézt v datovém zdroji text:
<SHOPITEM>(<ITEM_ID>(?P<id>.*?)<\/ITEM_ID>)?(<STOCK_QUANTITY>(?P<quatnity>.*?)<\/STOCK_QUANTITY>)?(<DELIVERY_TERM_ORDER>(?P<order>.*?)<\/DELIVERY_TERM_ORDER>)?(<DELIVERY_TERM_GET>(?P<get>.*?)<\/DELIVERY_TERM_GET>)?.*<\/SHOPITEM>
- Nahradit za text
<item id="\g<id>">
<stock_quantity>\g<quatnity></stock_quantity>
<delivery_time orderDeadline="\g<order>">\g<get></delivery_time>
</item>
- Zpracovat jako regulární výraz: ANO
Podívejme se na regulární výraz pro parsování dat podrobněji. Je složen z částí podobné viz níže. Na ní vysvětlím, co která část dělá.
(<ITEM_ID>(?P<id>.*?)</ITEM_ID>)?
- Vnější závorky (…něco…)? - ošetří, že celý element v shopitem být může a nemusí. Pokud by u dané shopitem tento element chyběl, zpracování se nerozbije.
- Vnitřní závorky (něco.*?) - označí data k vyparsování. Odpovídá zápisu (.*), tedy skupina s libovolným počtem libovolných znaků, jen je zapsána chytřeji, aby se data získala správně.
?P<id>- pojmenování proměnné. V tomto případě se proměnná bude jmenovat id.
Suma sumárum parsujeme hodnotu elementu, který být v datovém zdroji může, ale nemusí a obsah uložíme do proměnné, kterou si pojmenujeme. Toto je velmi šikovné.
Zápis dat
Zápis dat je jednoduchý. Proměnné označené jako \g<názevproměnné> vložíme do statického textu. V našem případě jde o proměnné id, quantity, order a get. Pojmenovali jsme si je sami při parsování viz. předchozí odstavec.
<item id="\g<id>">
<stock_quantity>\g<quatnity></stock_quantity>
<delivery_time orderDeadline="\g<order>">\g<get></delivery_time>
</item>
Uvedený postup lze zásadně zjednodušit. Stačí úvaha selským rozumem. Pokud např. drží e-shop veškeré zboží skladem a pokud má např. 5 ks, automaticky objednává u dodavatele novou dodávku zboží. S klidným srdcem bych do dostupnostního feedu zapsal všude počet kusů skladem stock_quantity jako 5 textem napevno. Bez proměnné. Tedy pokud by šlo o zboží prodávané kusově. Pokud by se kupovaly často větší počty kusů v jedné objednávce, bylo by třeba na situaci pohlédnout jinak. Podobně by bylo možné napevno bez proměnných zapsat i jiné části dostupnostního feedu.
![]() Všimněte si, že s výstupním textem pracuji jako s textem. Včetně odřádkování, mezer pro přehlednost a podobně. Vytvořit můžete téměř libovolnou strukturu.
Všimněte si, že s výstupním textem pracuji jako s textem. Včetně odřádkování, mezer pro přehlednost a podobně. Vytvořit můžete téměř libovolnou strukturu.
Shrnutí
Z produktového feedu jsme vytvořili feed Heureka dostupnostní. Ukázat jsem chtěl zejména principy získání a zápisu dat. Získání dat regulárním výrazem vypadá složitě, ale když se na něj podíváte pozorněji, zjistíte, že je docela jednoduchý. A v našem případě již řeší řadu nestandardních situací v datech. Dále jsme si ukázali, že získaná data můžeme zapsat do souboru zcela odlišné struktury - včetně různých zanoření, parametrů aj. Nechť je toto inspirací pro Vás, když budete řešit své “výzvy”. ![]()
Nechť vám Blending Bull slouží dobře.