Původně jsem počítal s tím, že Scraping Camel bude srapovat vždy všechna URL webu a pokud uživatel některá nebude chtít zpracovávat, vyloučí je v dalším zpracování. Např. v Mergadu. Dnešní release však přinesl funkci, která umožní vybrat, která URL webu zpracovávat a která nikoliv. Podívejme se na tuto funkcionalitu podrobněji.
Proč crawlovat (někdy) jen vybraná URL
Představte si, že chcete zpracovávat např. jen kategorie e-shopu (bez produktových a jiných stránek), pouze produktové stránky, pouze stránky blogu atp. V takovém případě by crawlování celého webu bylo zbytečné. Zbytečně by zatěžovalo web, intervaly aktualizace dat by byly delší, výstupní CSV feed by obsahoval řádky, které nepotřebujete. Vyloučení nepotřebných URL tedy zvýší efektivitu zpracování dat a vyčistí výstupní feed.
Jak nastavit URL pro scrapování
Na stránce Nastavení webu vespod můžete nastavit která URL vyloučit nebo naopak která stahovat. A to zadáním řetězce z URL nebo regulárního výrazu. Podmínek můžete uvést více.
Co nastavení URL udělá
Stránky se vám na stránce Stránky objeví. Budou mít ovšem červený symbol, nebudou se scrapovat ani exportovat do výstupních feedů.
Příklady různých typů stránek
Pro inspiraci uvedu několik typů stránek, aby bylo jasné, že weby obvykle nejsou homogenní. Různé typy stránek mohou mít různé vlastnosti. A různý účel. Například stránka blogu asi nebude mít vlastnost cena, zatímco u produktové stránky e-shopu by cena býti měla ![]()
Typy stránek:
- produktový detail
- produktová kategorie
- článek
- běžná stránka “statická”
- stránka s kontakty, obchodní podmínky… (příklad, že některé typy lze dále dělit)
- hlavní stránka webu
- …
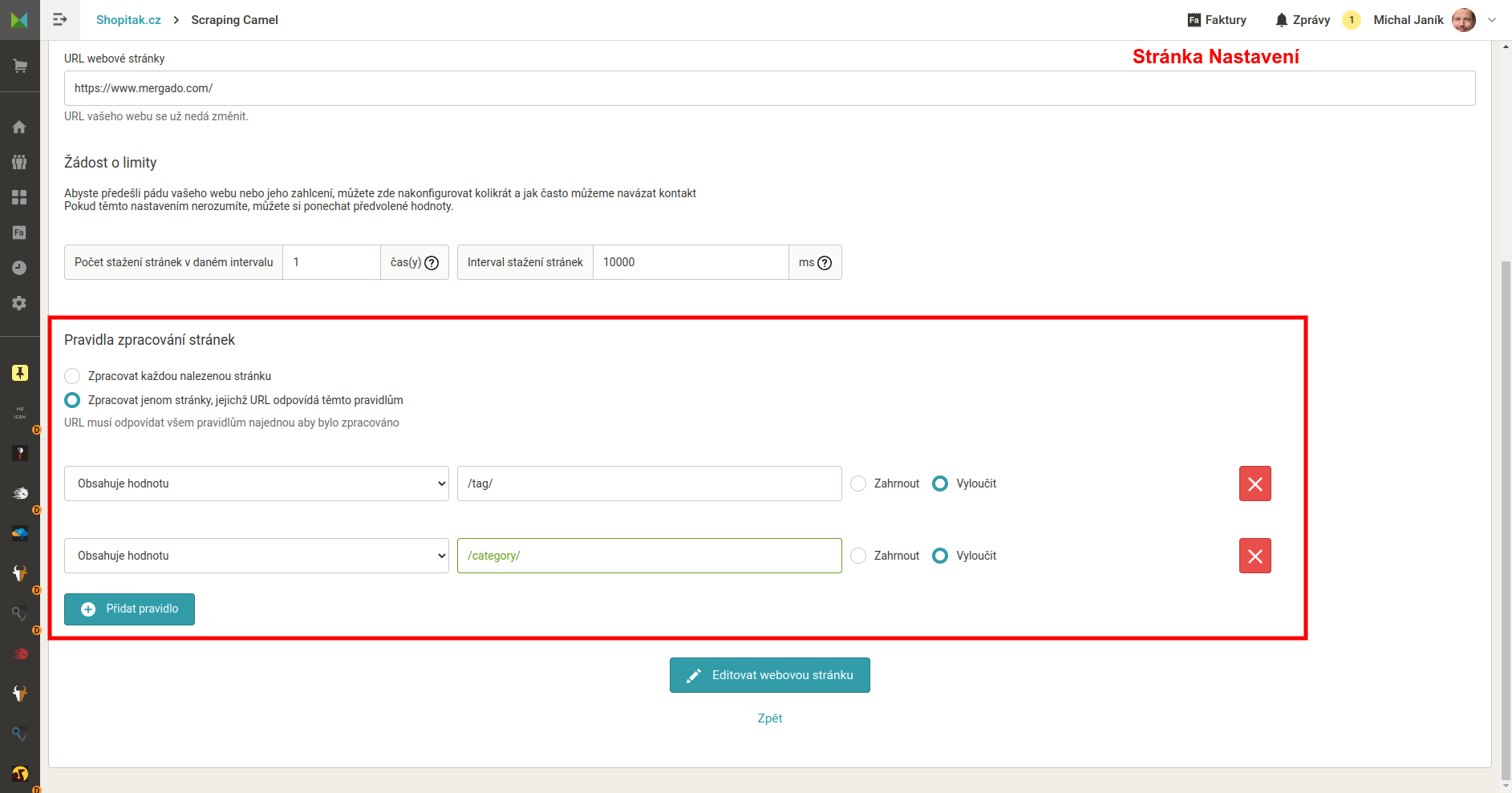
Příklad nastavení scrapovaných URL.