Na svět přišla nová aplikace ![]() Scraping Camel.
Scraping Camel.
Rád bych na ni @group_specialists @group_feedmarketing upozornil.
 Co dělá Scraping Camel
Co dělá Scraping Camel
Prochází HTML stránky webu. Získává z nich informace. Tyto informace uloží a vygeneruje z nich jeden výstupní CSV soubor.

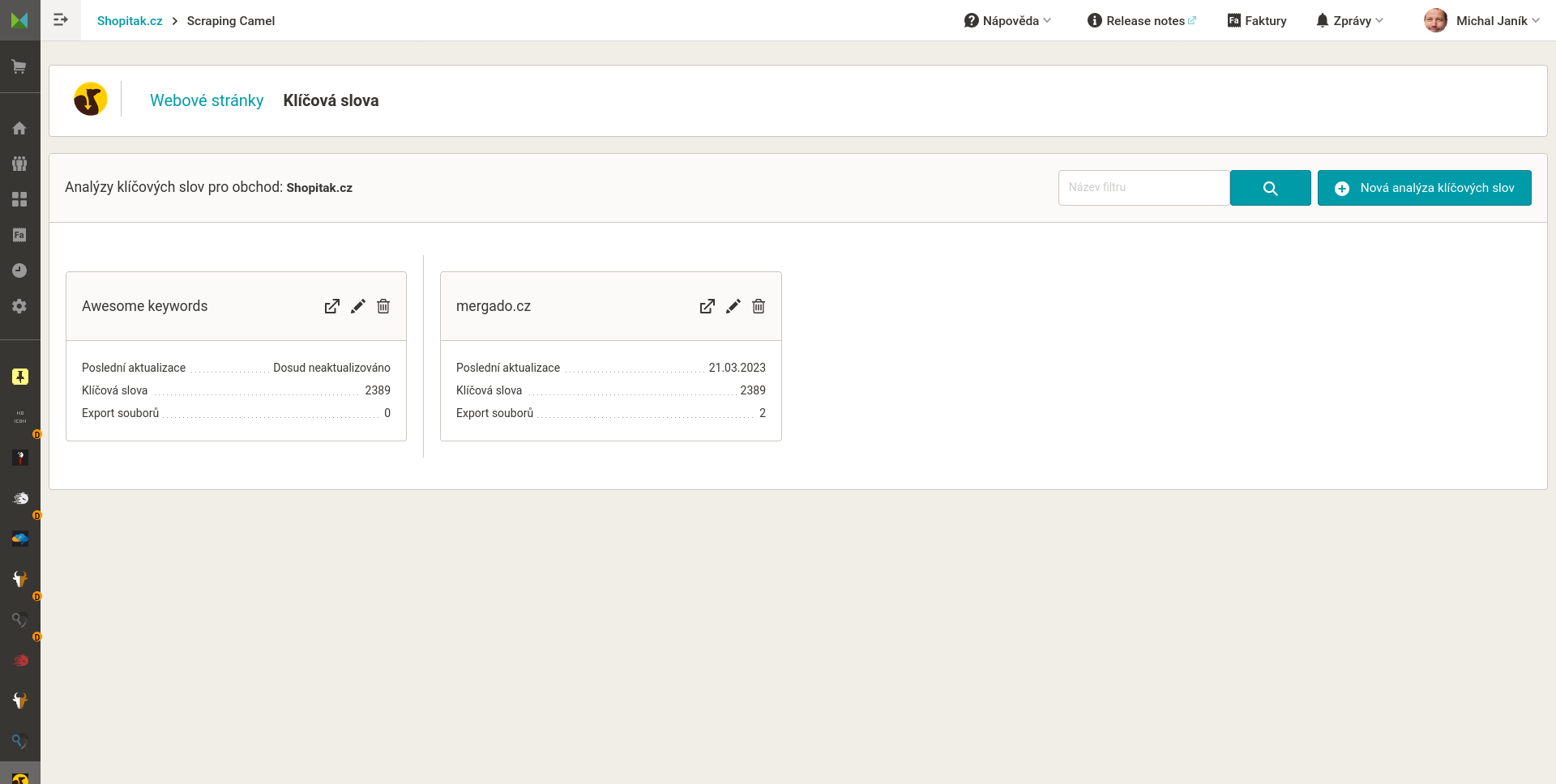
 K čemu jsou data v CSV dobrá
K čemu jsou data v CSV dobrá
Při návrhu aplikace jsem myslel na dvě hlavní využití.
1) Zpracování dat které ve standardních produktových feedech nejsou
![]() Těchto dat, co ve feedech nejsou a mohou se přitom hodit je celá řada. Jednou z příčin může být to, že ve standardních produktových feedech jsou data o produktových stránkách. Chybí ovšem data o stránkách kategorií, statických stránkách s kontakty, obchodními podmínkami a podobně!
Těchto dat, co ve feedech nejsou a mohou se přitom hodit je celá řada. Jednou z příčin může být to, že ve standardních produktových feedech jsou data o produktových stránkách. Chybí ovšem data o stránkách kategorií, statických stránkách s kontakty, obchodními podmínkami a podobně!
![]() Druhým důvodem může být, že jde o web bez košíku, který datové feedy vůbec nemá. Ano, Scraping Camel může zpracovat i web bez košíku, nikoliv jen e-shop.
Druhým důvodem může být, že jde o web bez košíku, který datové feedy vůbec nemá. Ano, Scraping Camel může zpracovat i web bez košíku, nikoliv jen e-shop.
![]() Dalším důvodem může být to, že chcete získat informace, které jsou v samotných stránkách webu, CMS však informace o např. dostupnosti, benefitech, parametrech a podobně negeneruje do feedu. Nemusí jít přitom o klasická produktová data. Můžete si vyparsovat libovolnou část HTML kódu stránky. Můžete tedy parsovat např. klasická „SEO data“ jako TITLE, META DESCRIPTION, H1 a podobně. Nebo si můžete vyparsovat např. ID značky Google Analytics či Google Tag Manageru, abyste ověřili zda jsou na všech stránkách, resp. kde chybí atp.
Dalším důvodem může být to, že chcete získat informace, které jsou v samotných stránkách webu, CMS však informace o např. dostupnosti, benefitech, parametrech a podobně negeneruje do feedu. Nemusí jít přitom o klasická produktová data. Můžete si vyparsovat libovolnou část HTML kódu stránky. Můžete tedy parsovat např. klasická „SEO data“ jako TITLE, META DESCRIPTION, H1 a podobně. Nebo si můžete vyparsovat např. ID značky Google Analytics či Google Tag Manageru, abyste ověřili zda jsou na všech stránkách, resp. kde chybí atp.
Můžete z HTML stránek získat téměř libovolná data, což může být velmi mocné.
2) Tvorba feedů pro stránky, které datové feedy nemají
Zejména v zahraničí stále existují e-shopy, které nemají XML či CSV feedy s produktovými daty. Ty mohou Scraping Camel využít na tvorbu produktových feedů. Zpracování si přitom nastavíte sami. Nemusíte žádat administrátora aplikace.
 Jak funguje Scraping Camel
Jak funguje Scraping Camel
- Úvodní nastavení
- Uživatel vytvoří „web“. Jde o obdobu exportu v Mergadu. De facto jde o jednu doménu. Webů může být v jedné instalaci Scraping Camel více.
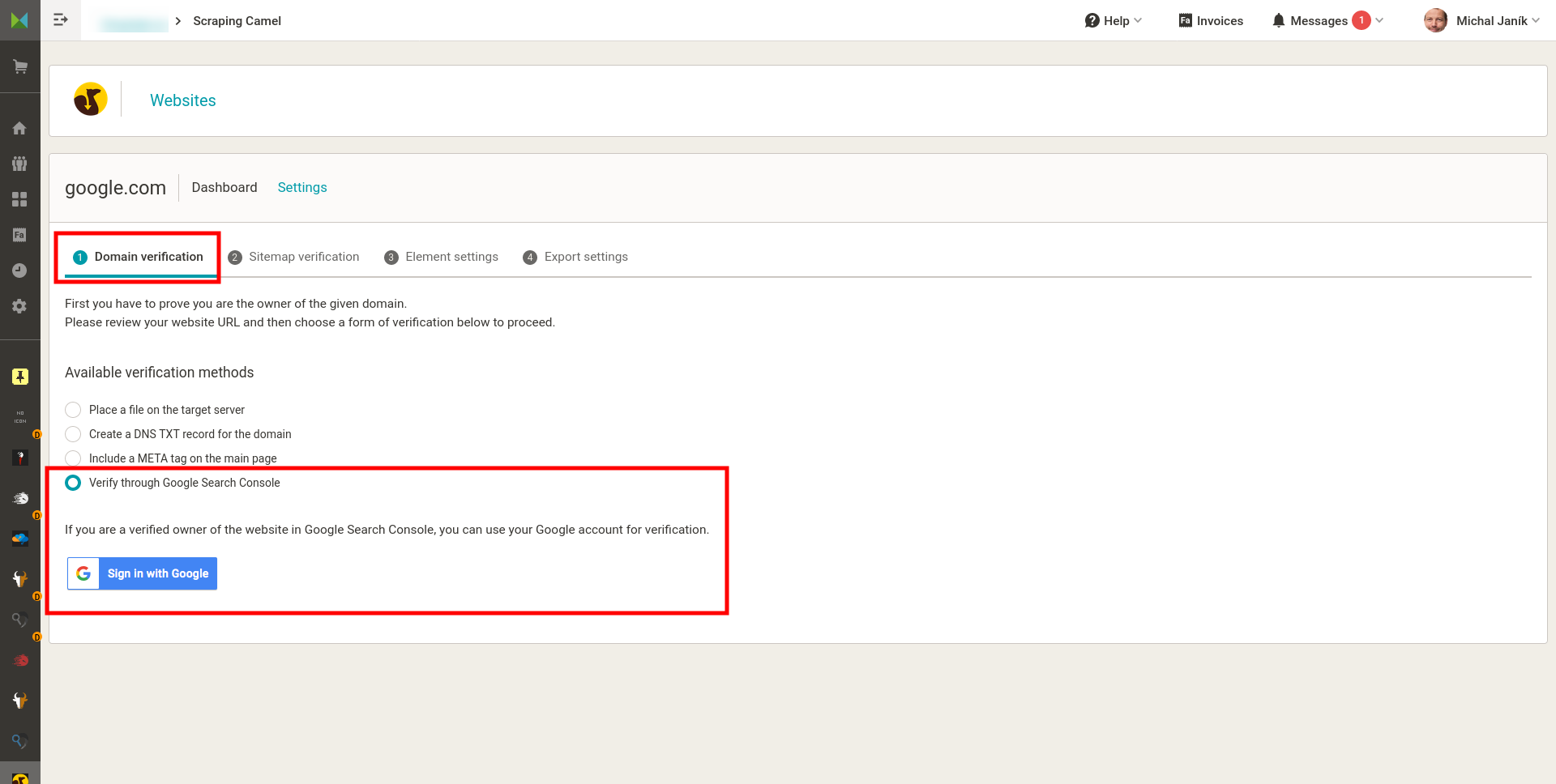
- Ověření domény - podobně jako u Google je třeba ověřit vztah k doméně. Na výběr je z vložení souboru do webu, META TAG či DNS záznam. Scrapovat cizí weby nyní není cílem aplikace.
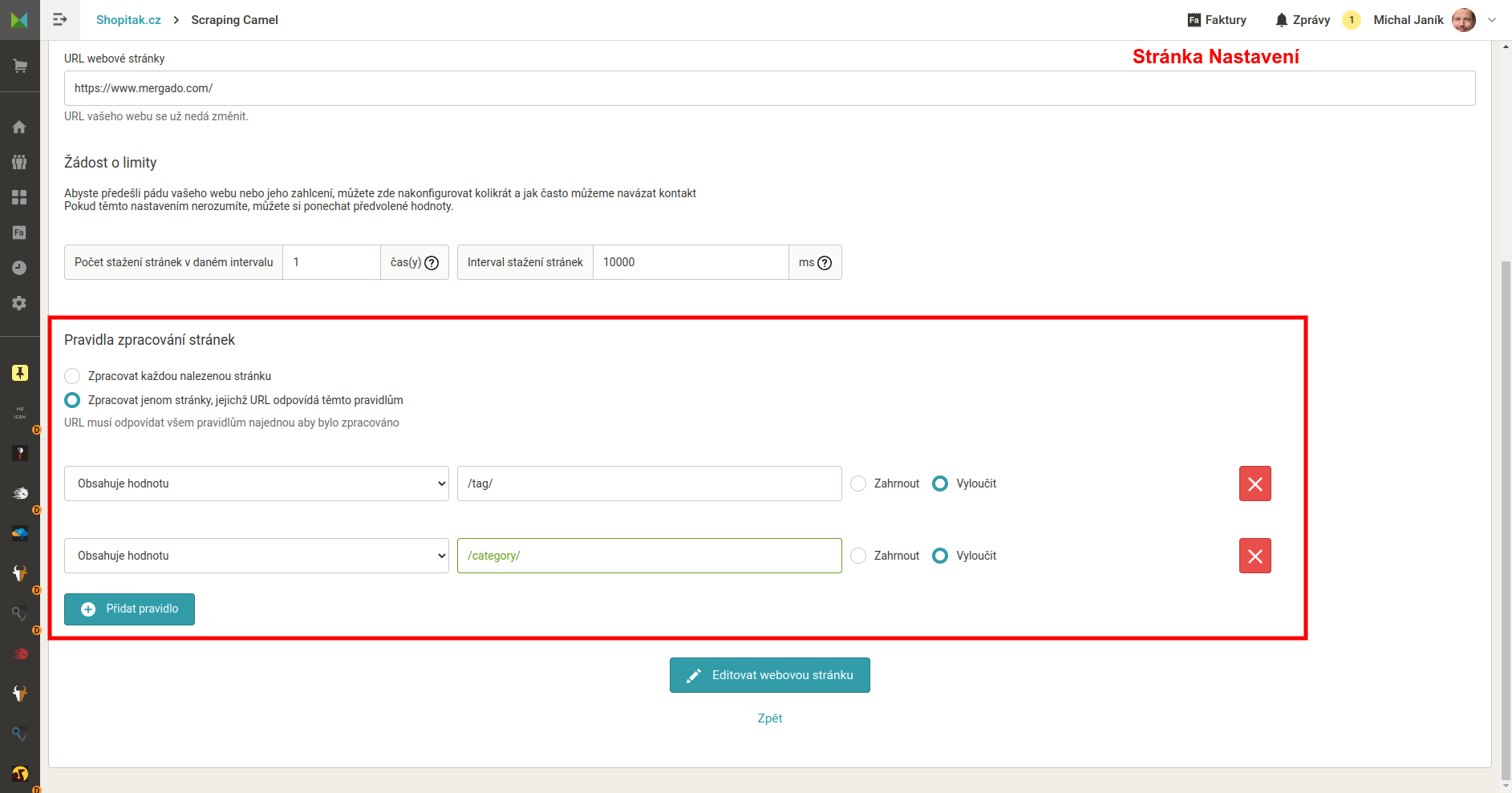
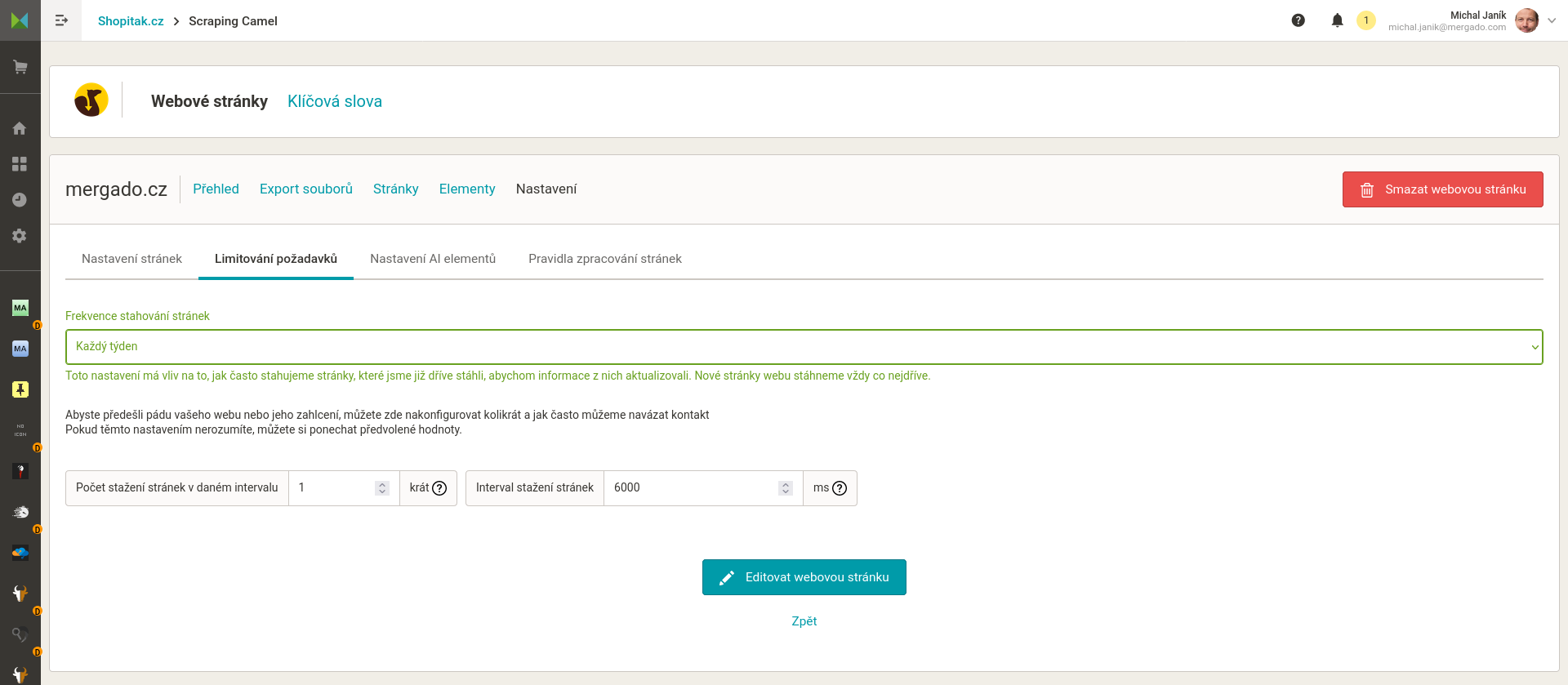
- Vložení sitemap.xml a nastavení webu. Sitemap.xml je podmínkou fungování aplikace. Zde bere Camel URL stránek webu. Pozor na nastavení, uživatel nastavuje frekvenci procházení stránek webu. Příliš mnoho dotazů naráz by mohlo vést k přetížení webu. Příliš málo povede k tomu, že zpracování celého webu bude trvat dlouho.
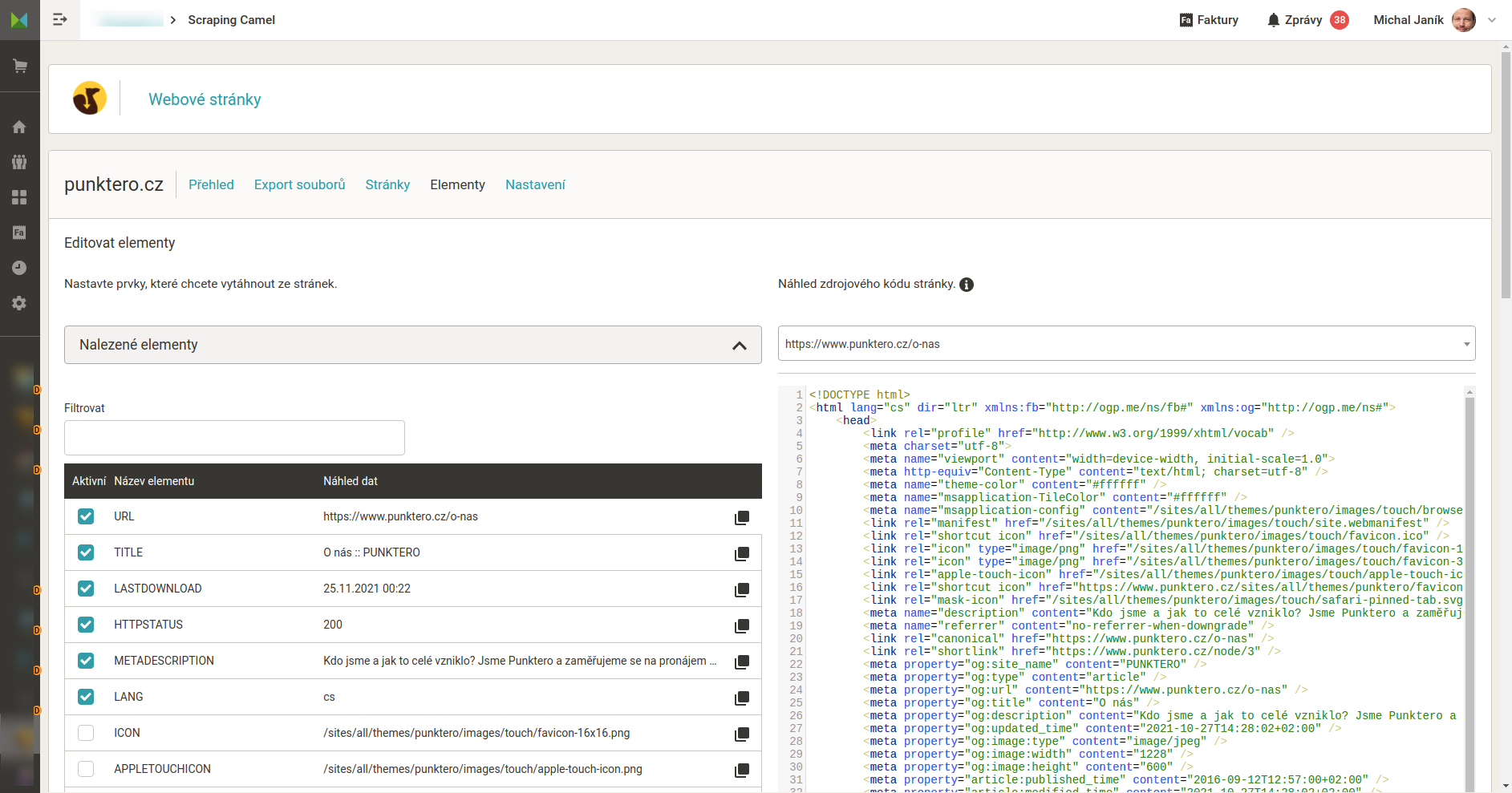
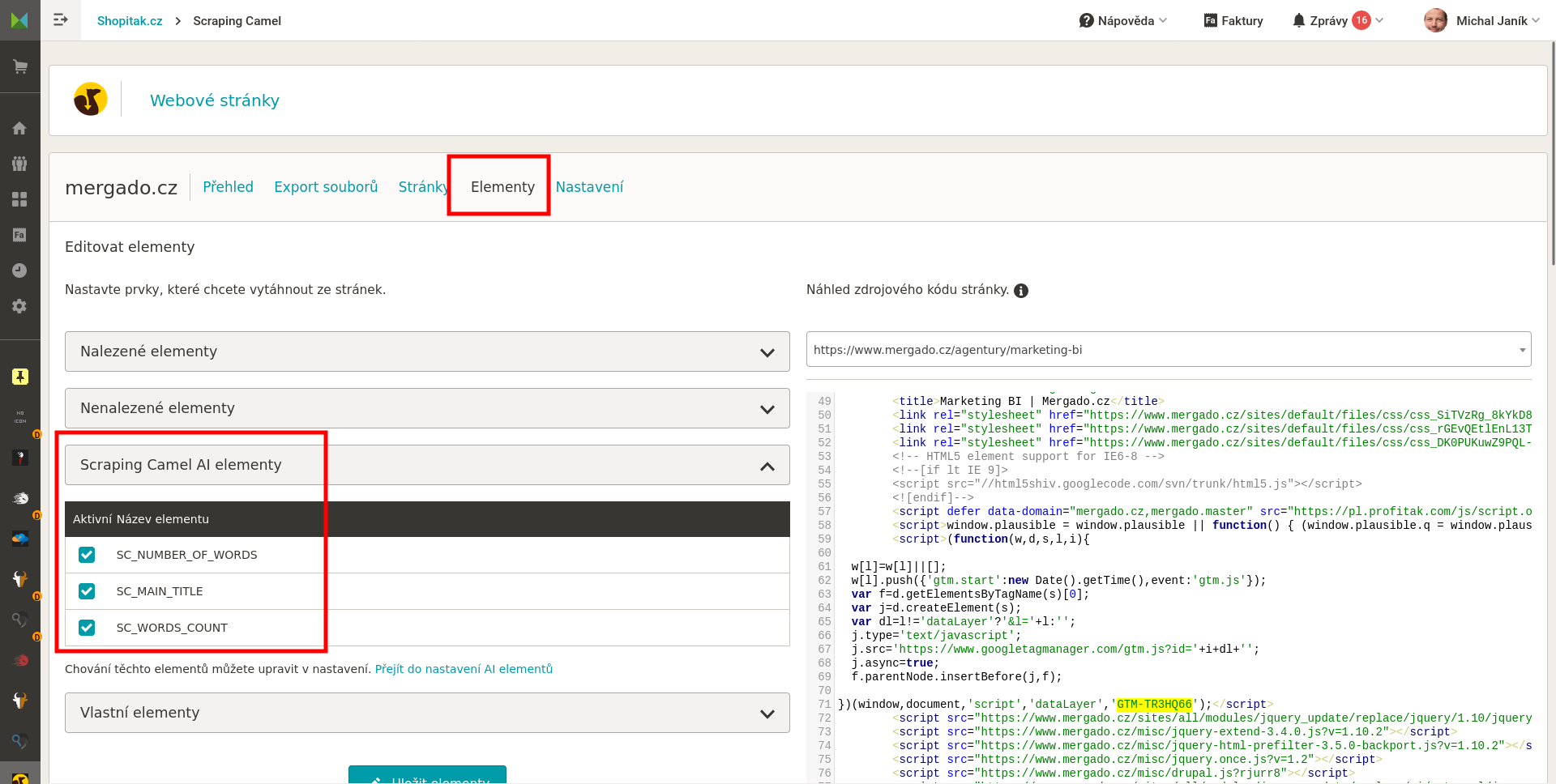
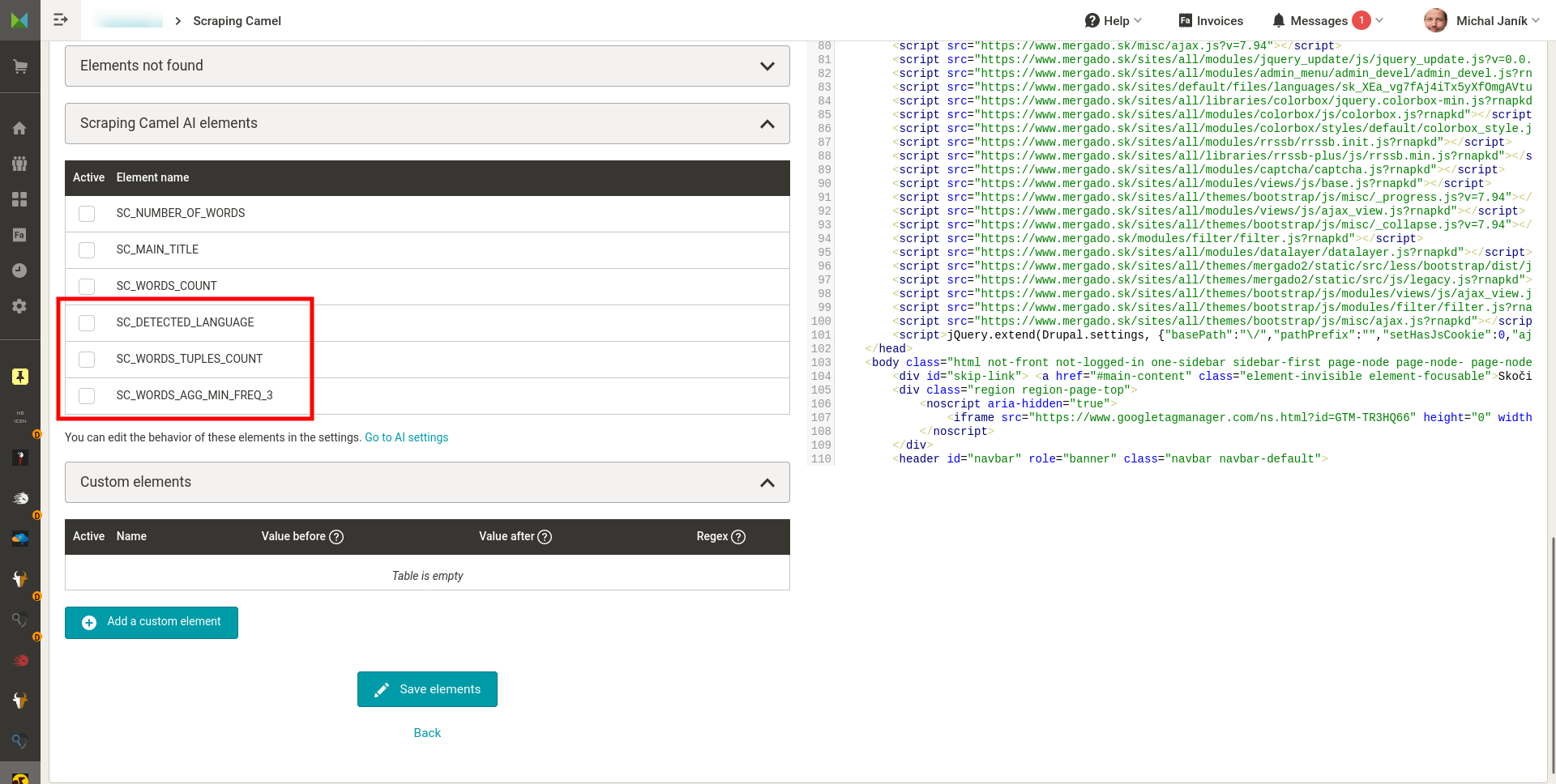
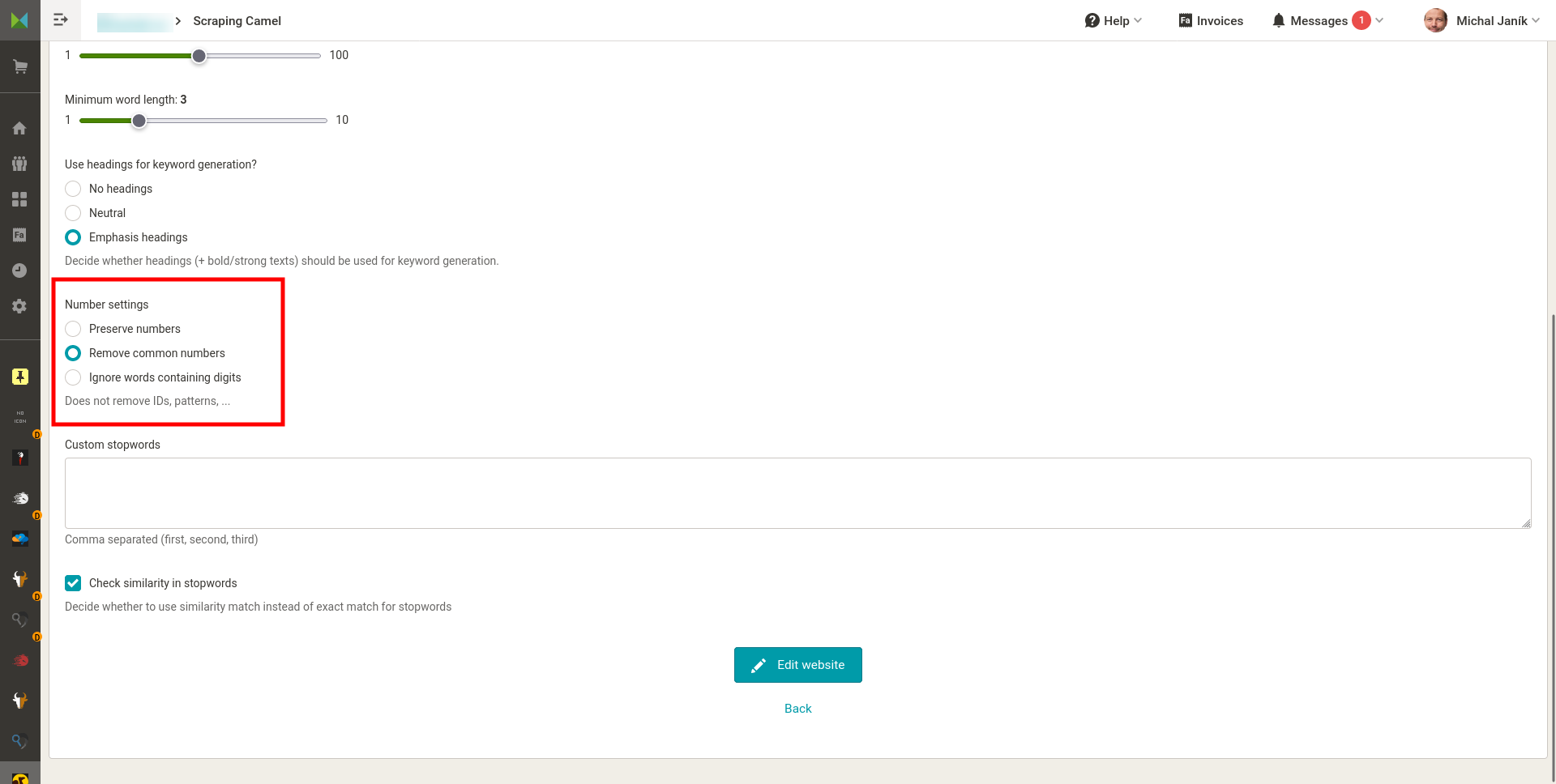
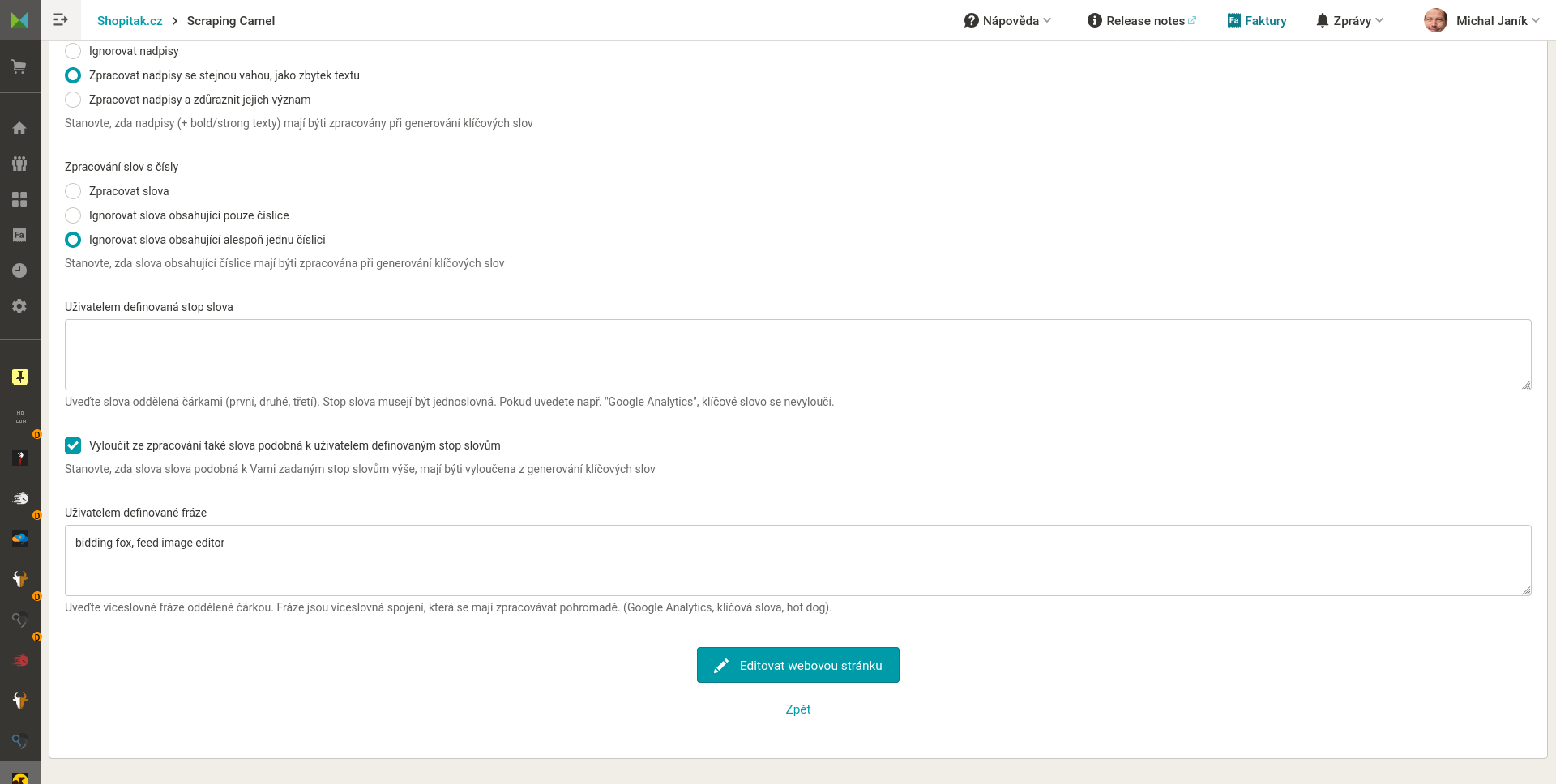
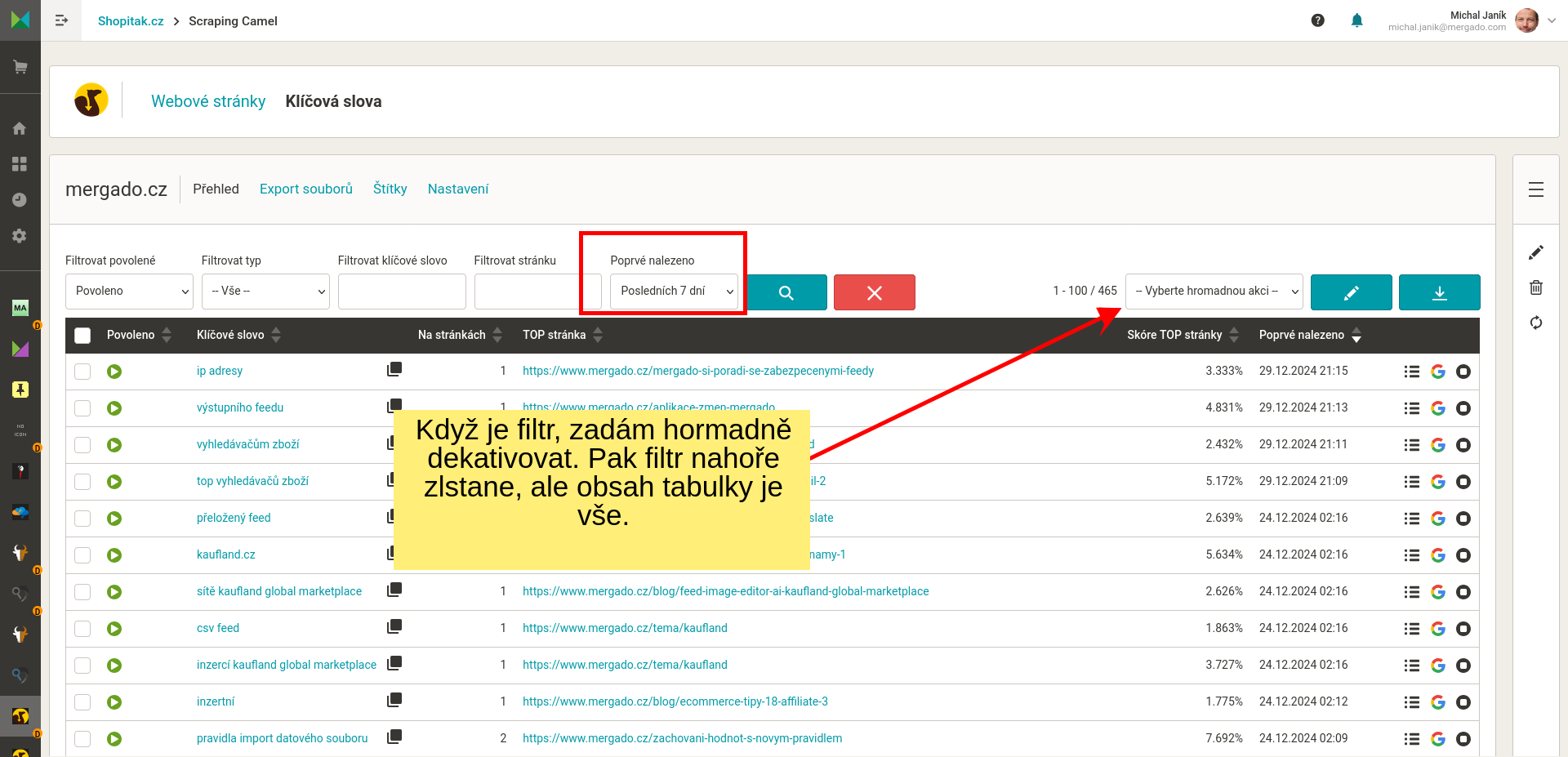
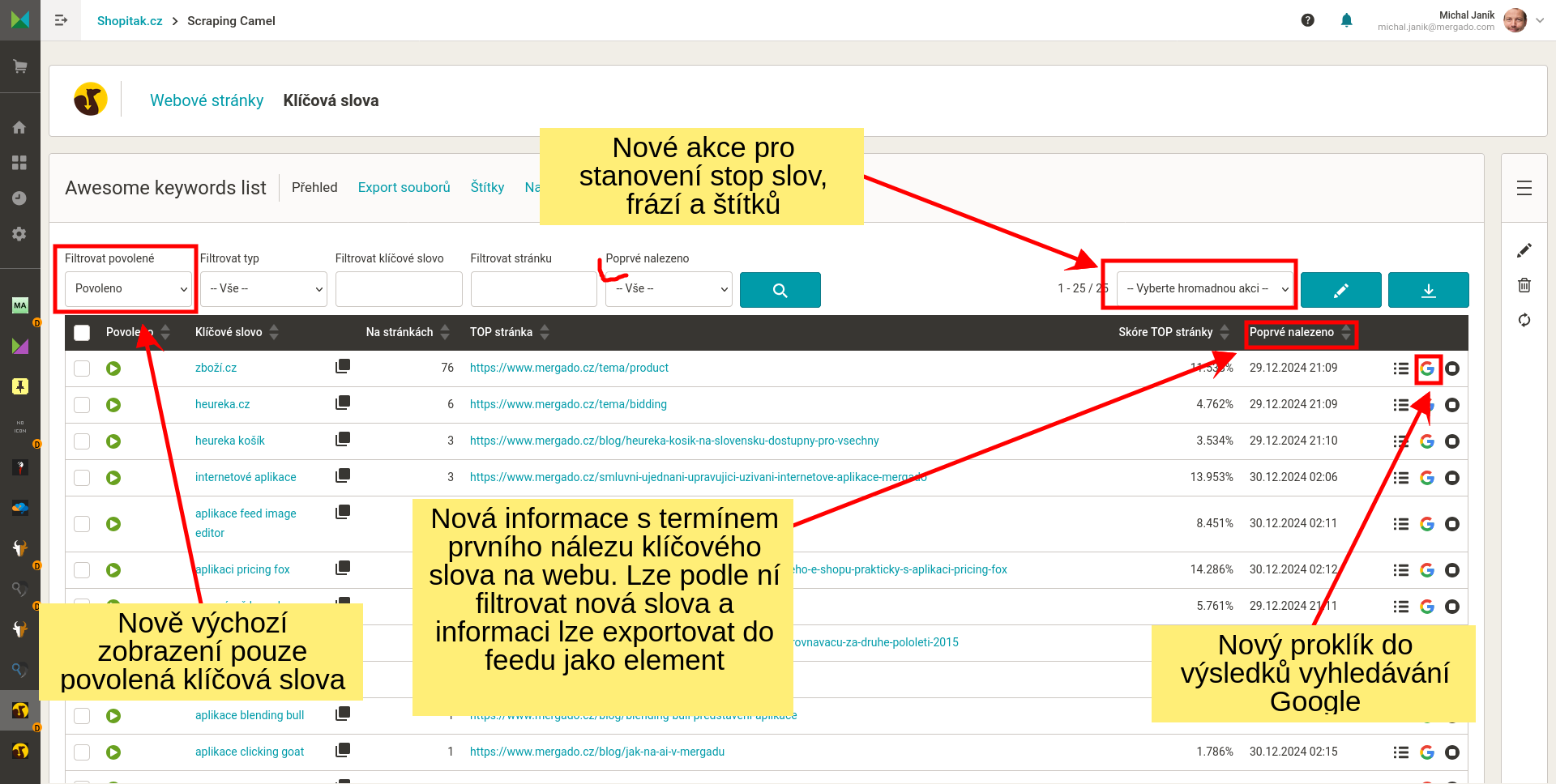
- Nastavení jaká data má Camel z HTML stránek získávat. Na výběr je pár základních elementů. Předpokládám, že každý využije vlastní elementy, které nastaví buď uvedením textů před a za hledanými informacemi, nebo za použití regulárního výrazu.
- Nastavení jak se mají jmenovat data (sloupečky) ve výstupním CSV souboru.
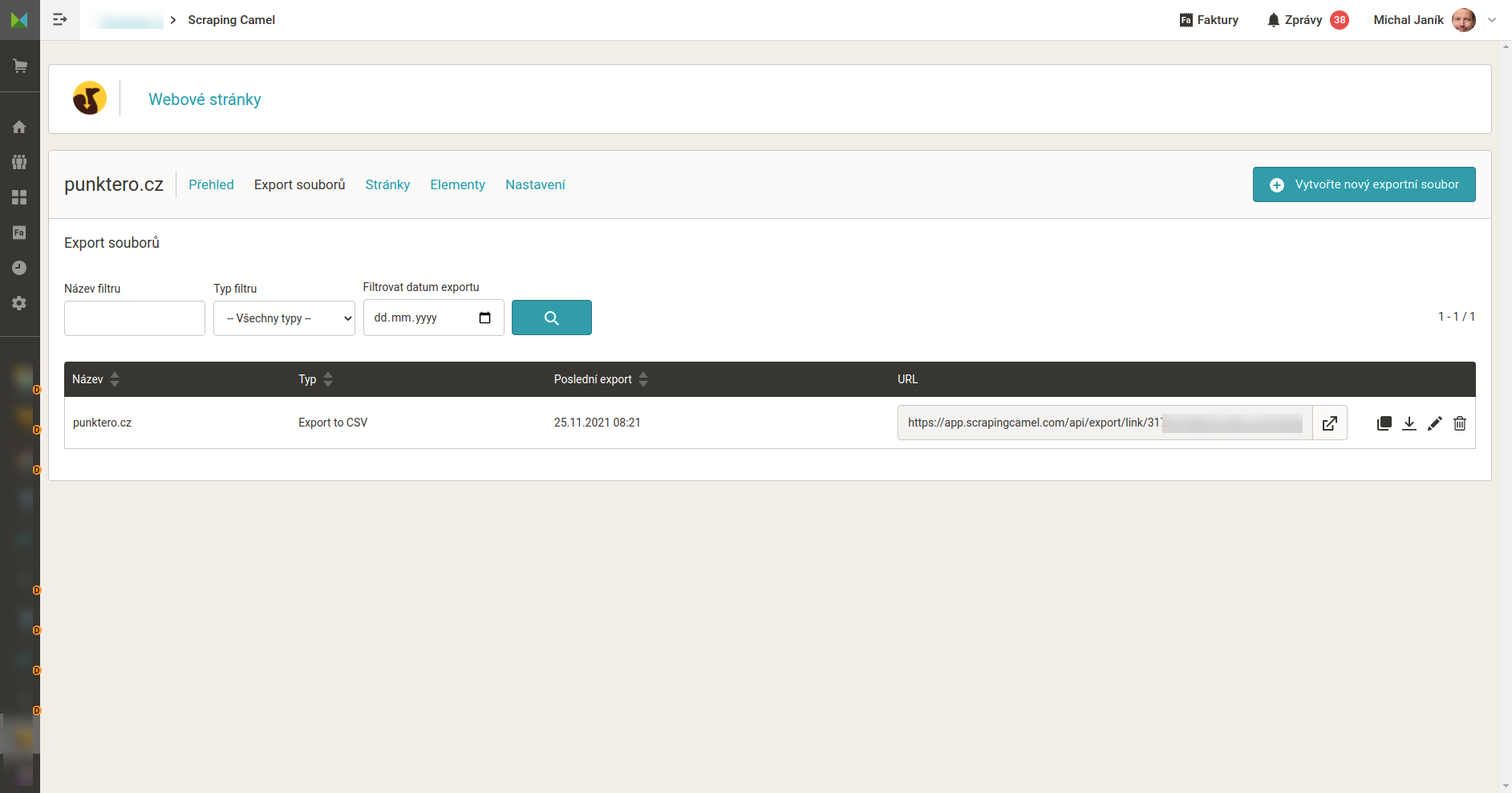
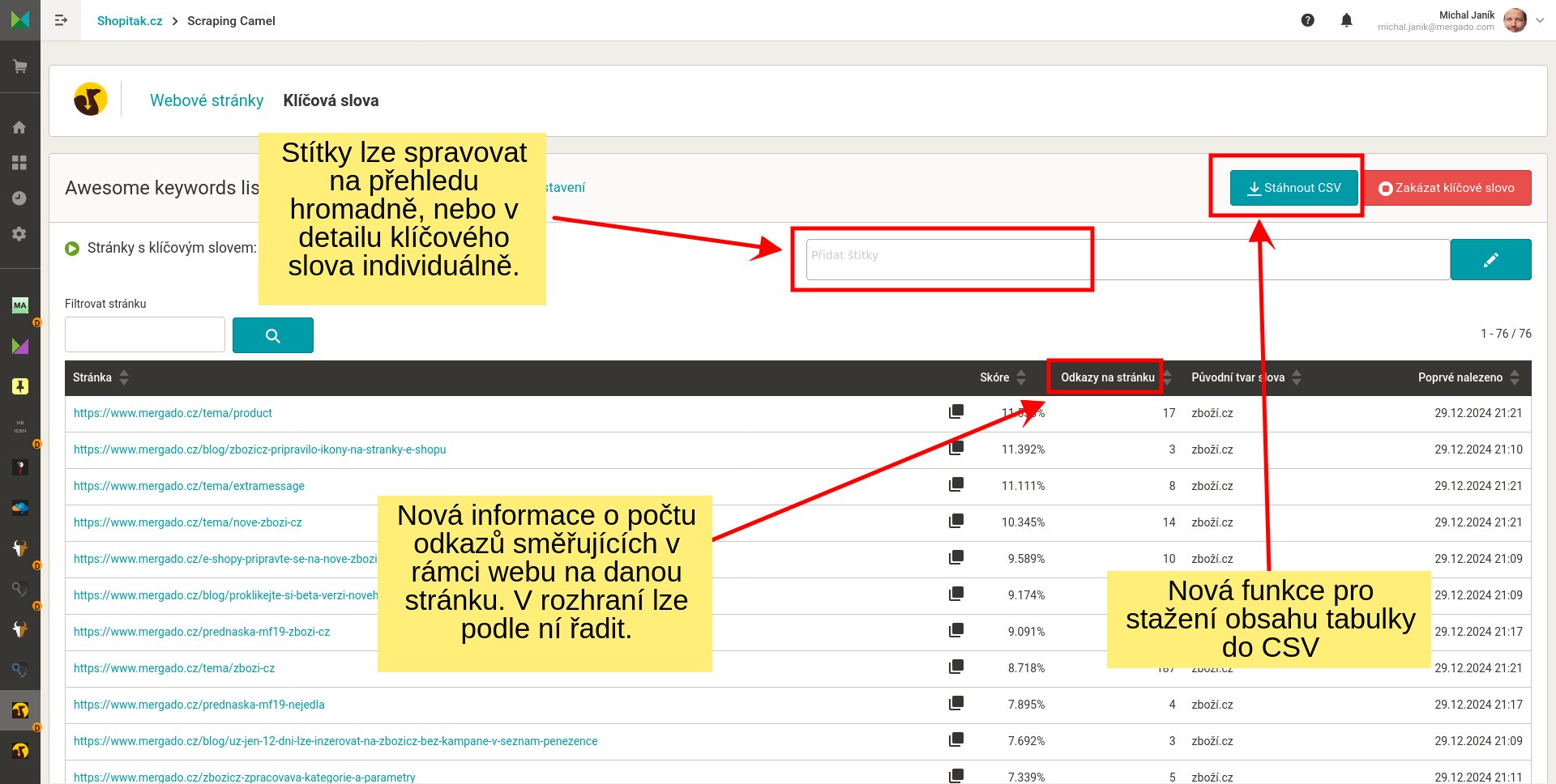
- Po ukončení nastavování začne Scraping Camel procházet cílový web. To bude nějakou dobu trvat. Až celý web zpracuje, vygeneruje výstupní CSV a v administraci uvede jeho adresu.
- Dlouhodobá činnost:
- Scraping Camel sám, pravidelně kontroluje sitemap.xml zda se objevily nové stránky. Kontroluje všechny stránky a případné změny promítne do výstupního CSV souboru.
Možná vás napadla podobnost Scraping Camel se známými SEO crawlery. Zatímco ty obvykle spouští uživatel jednorázově na svém počítači, Scarping Camel běží na serveru, non-stop. Výstupy poskytuje ve strojově čitelné podobě, co lze dále strojově zpracovávat. Lze ho využít jak k jednorázovým analýzám, tak lze data automaticky zpracovávat dalším software.
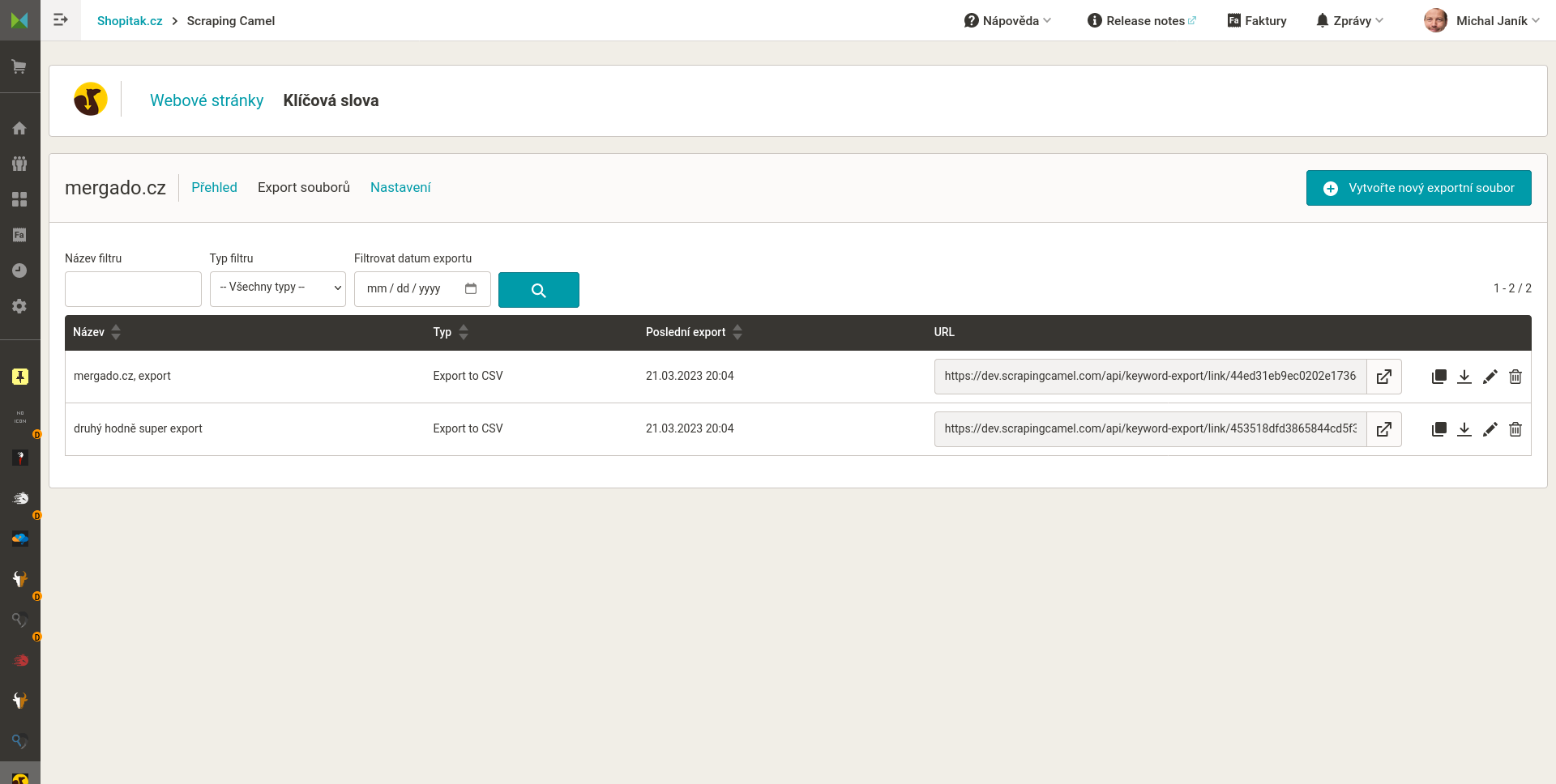
 Využití výstupního CSV souboru
Využití výstupního CSV souboru
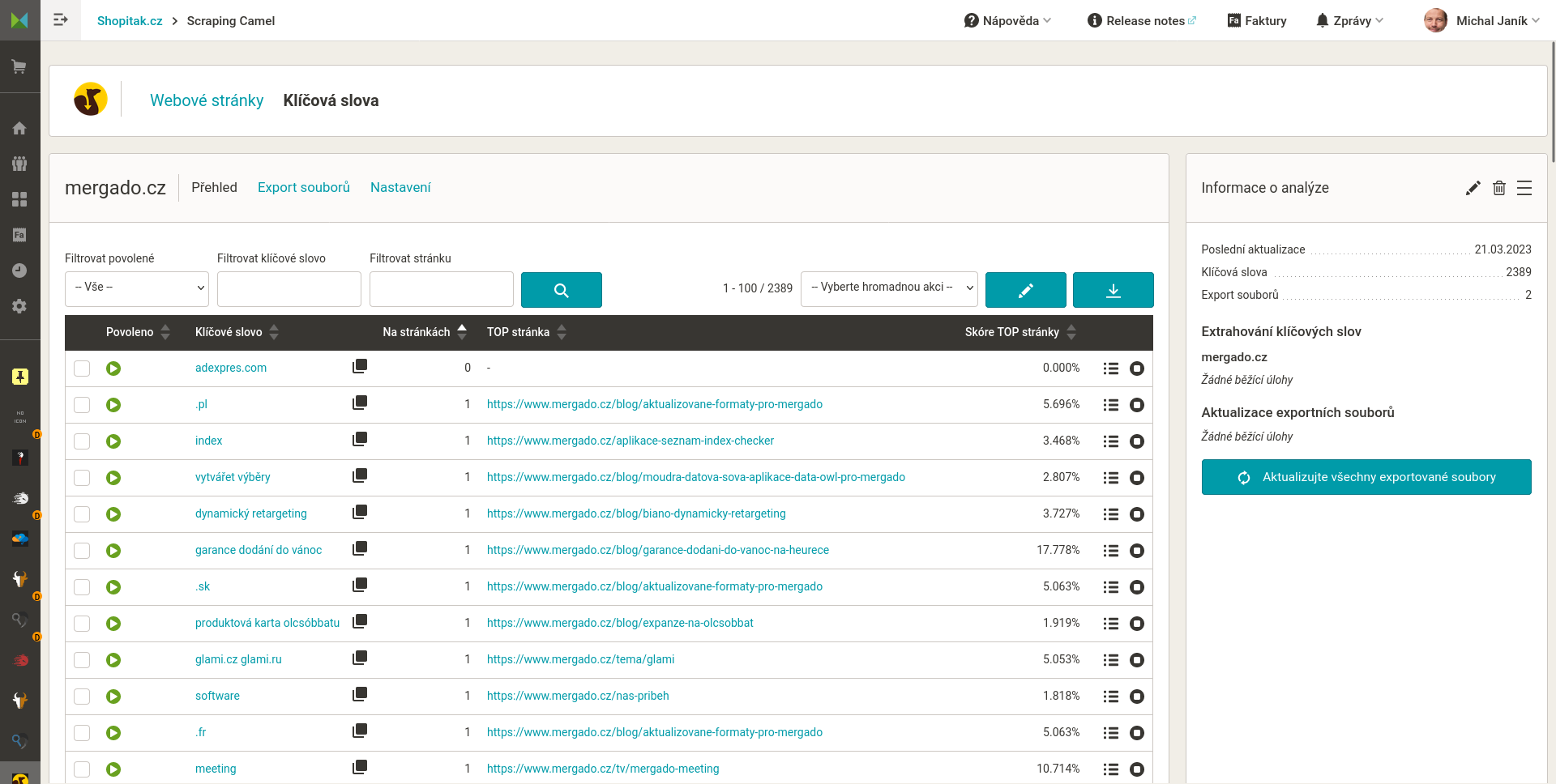
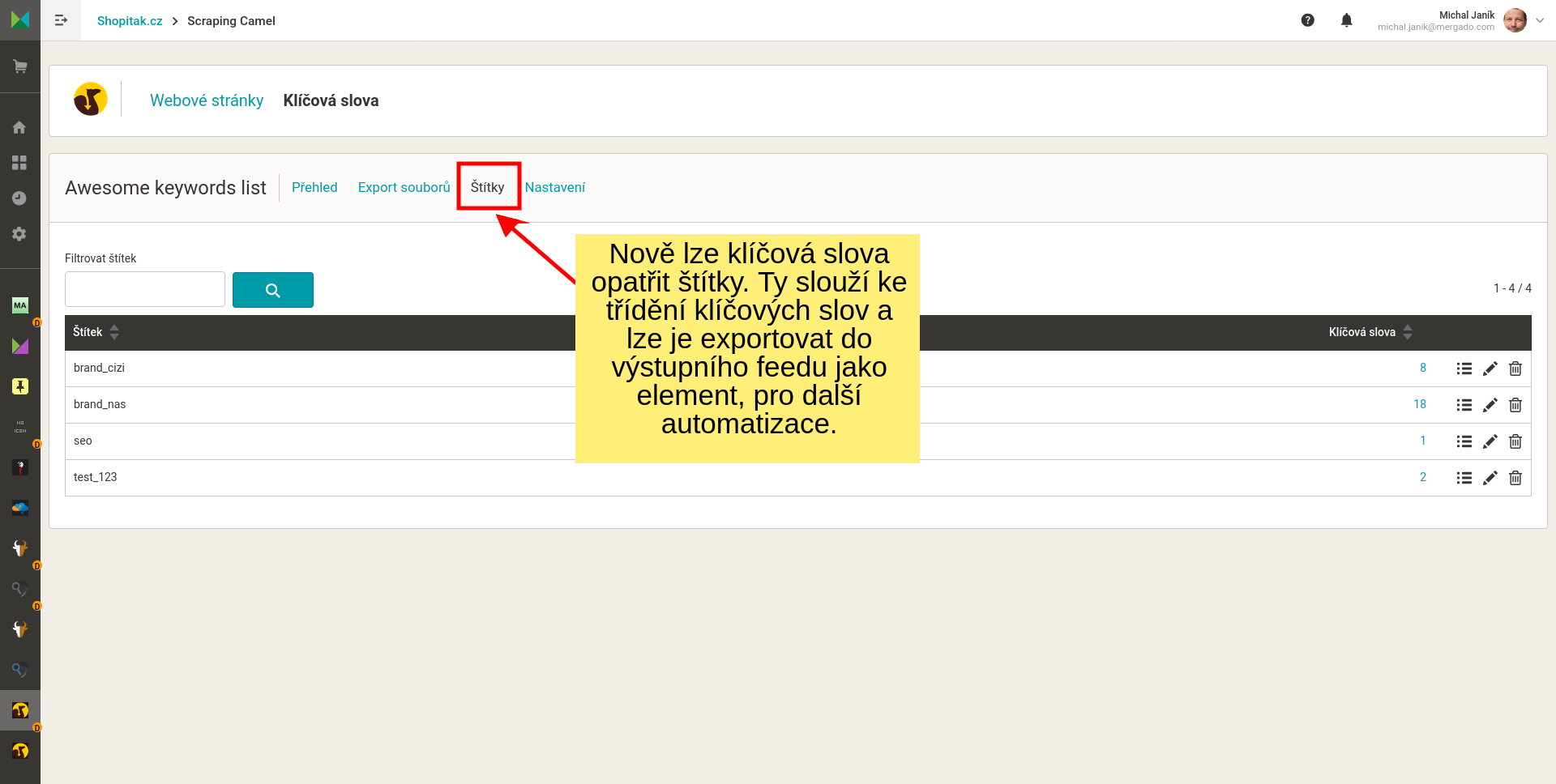
CSV feed jsem zvolil proto, že je obecný. Lze ho otevřít v běžných kancelářských programech. Dále jej lze dobře strojově zpracovat.
- Nahrát do Mergada jako vstupní soubor pro export a s tímto dále pracovat obvyklým způsobem.
- Pravidlem datový import napojit data z CSV do existujícího exportu v Mergadu.
- Zpracovat v jiné aplikaci.
 Příklady využití dat z CSV feedů
Příklady využití dat z CSV feedů
Využití je široké. Uvedu příklady.
- SEO analýzy, kontroly stránek, měřících skriptů aj.
- Datové analýzy produktů, stránek aj.
- Reklamní kampaně postavené na datech z feedu - DSA kampaně aj.
- …a další
… a to i když není omezena, že musí zpracovávat stejnou doménu - nemusí. Cílem je to, že e-shop v Mergadu umožňuje spravovat přístupy uživatelů. Navíc se domnívám, že data náležejí obvykle nějakému e-shopu (či webu bez košíku) resp. nějaké společnosti či lidem. Pokud tedy Camel nasadí např. agentura, dává smysl zapnout aplikaci na e-shopu klienta. Např. pro to, že až jednou spolupráce s klientem skončí, Camela i s nastavením bude moci klientovi předat.
Jak je na tom aplikace nyní
V Mergado Store nyní můžete zkoušet verzi 1.0. Ta prošla testováním a je plně funkční. Máme v plánu vylepšit české texty v aplikaci tak, aby byla aplikace lépe k pochopení. To ovšem nemá vliv na funkčnost.
 Jak vypadá Scraping Camel
Jak vypadá Scraping Camel
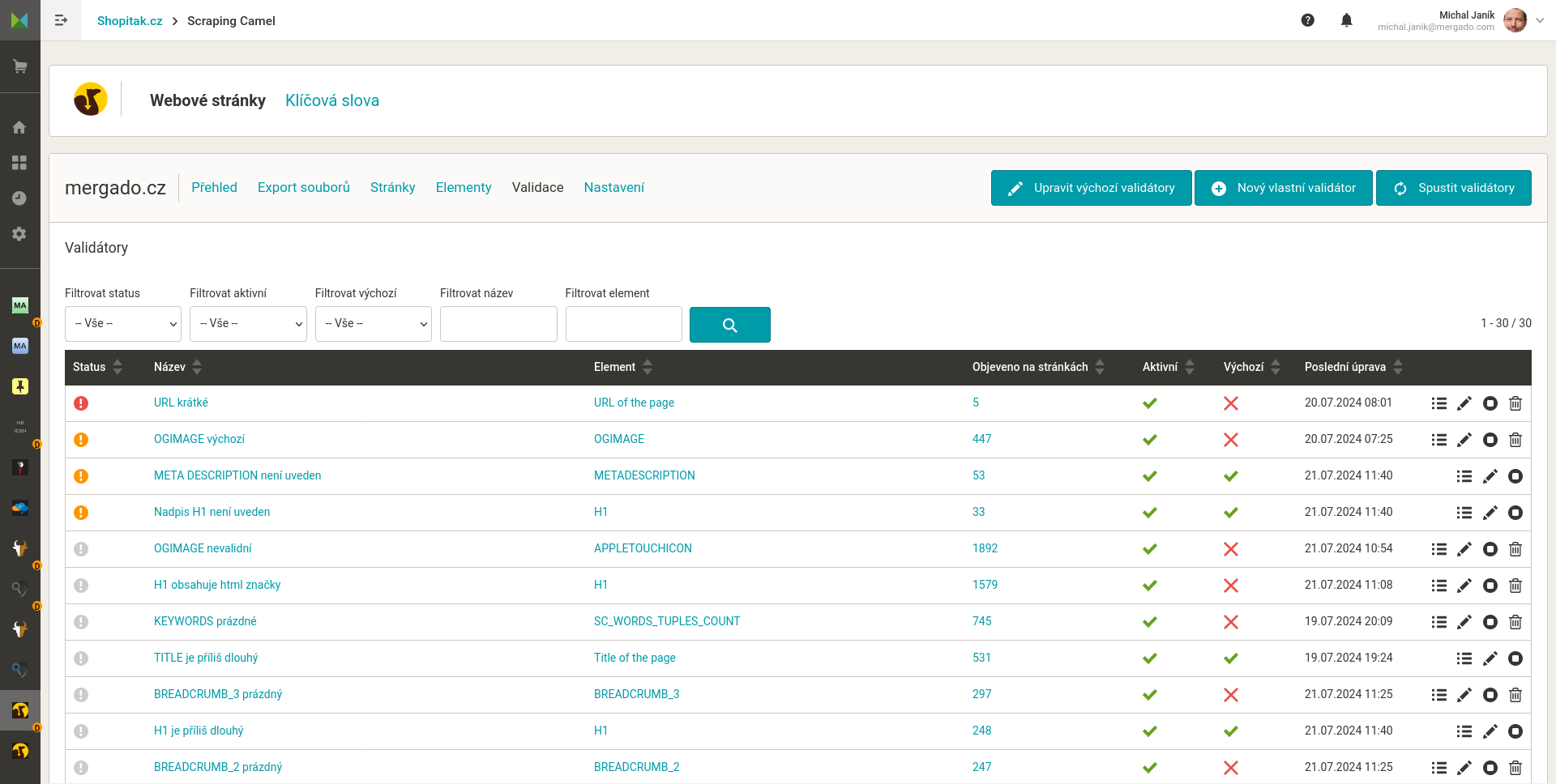
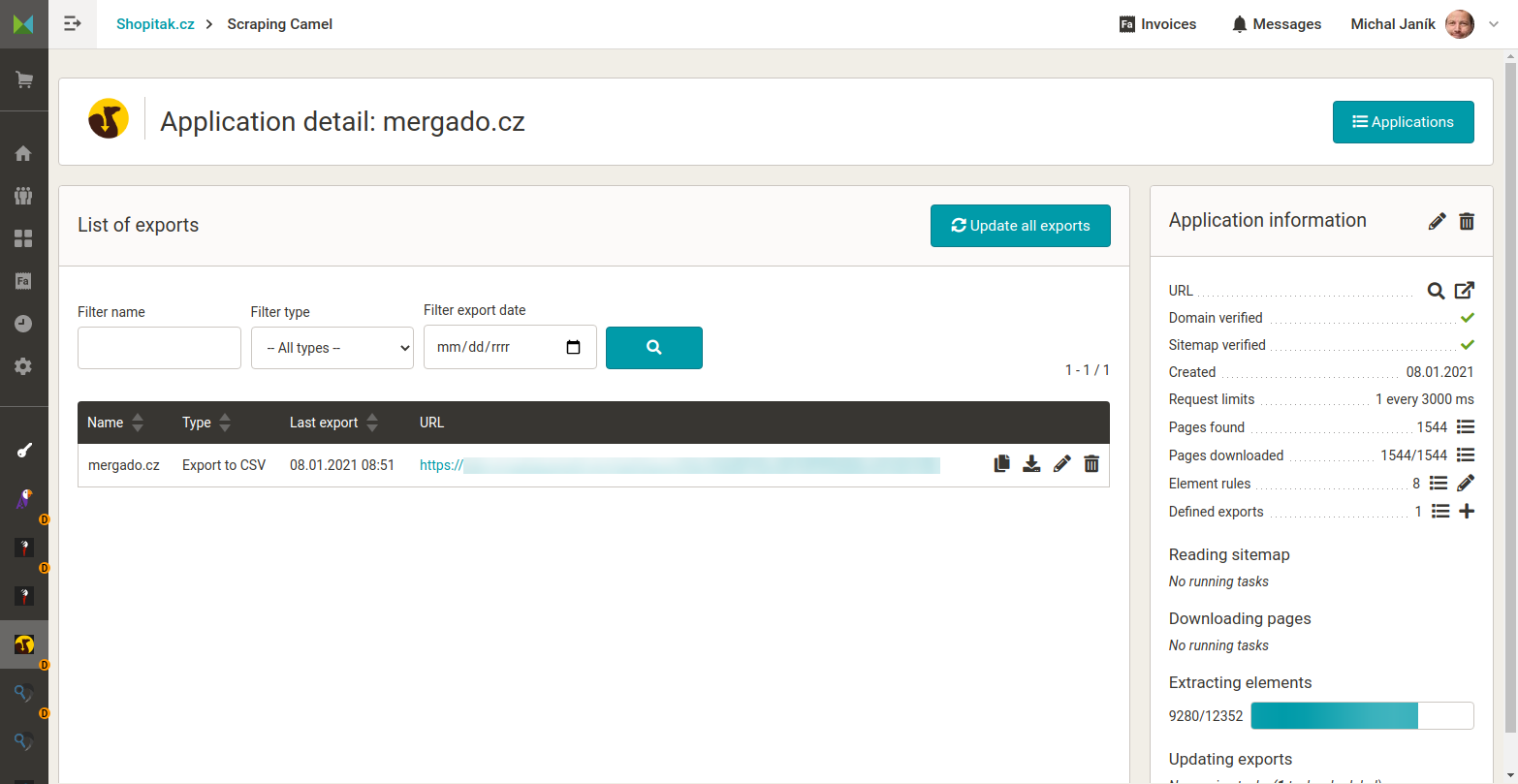
Hlavní stránka „webu“ s nastaveními a URL výstupného CSV
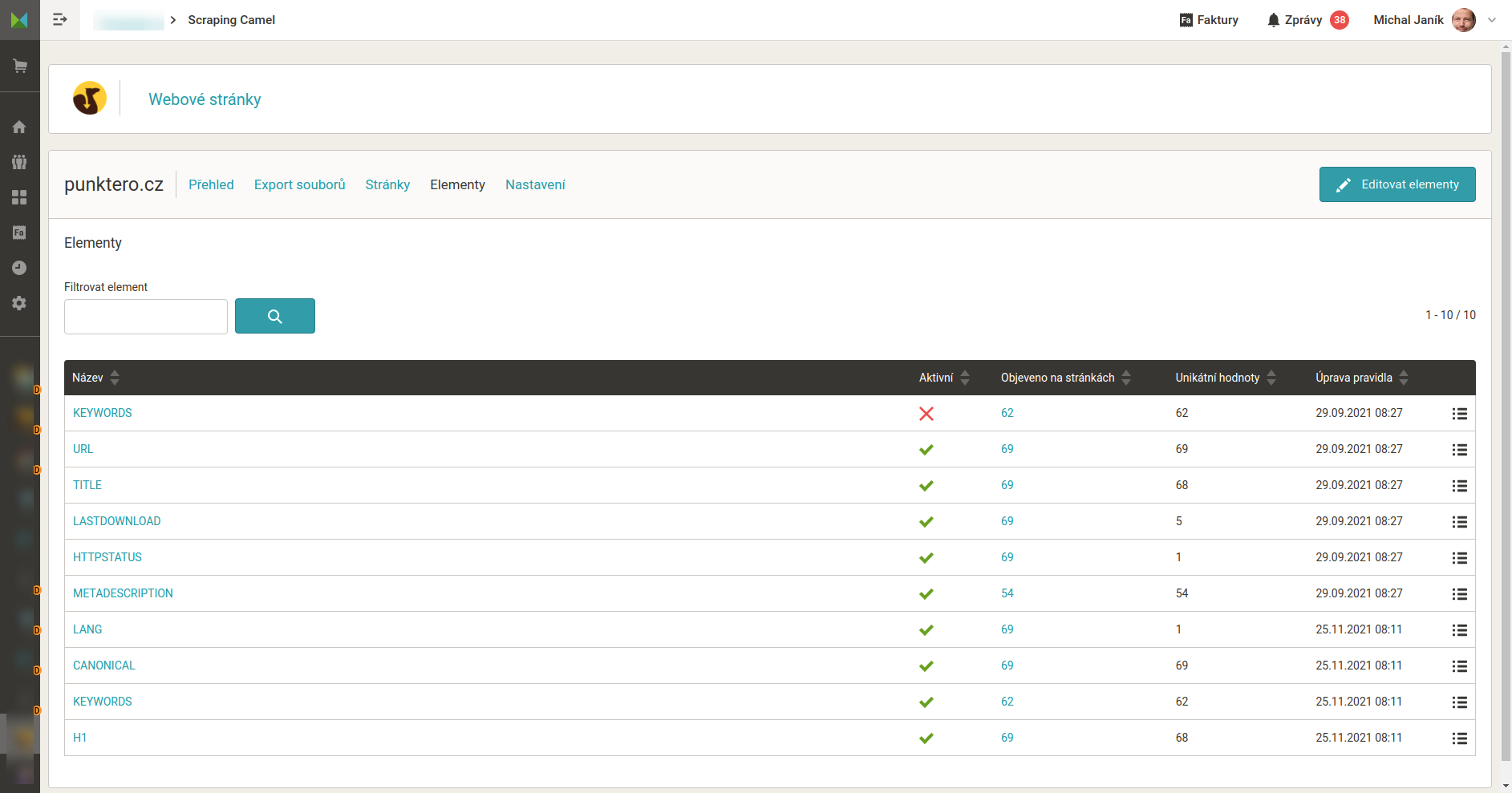
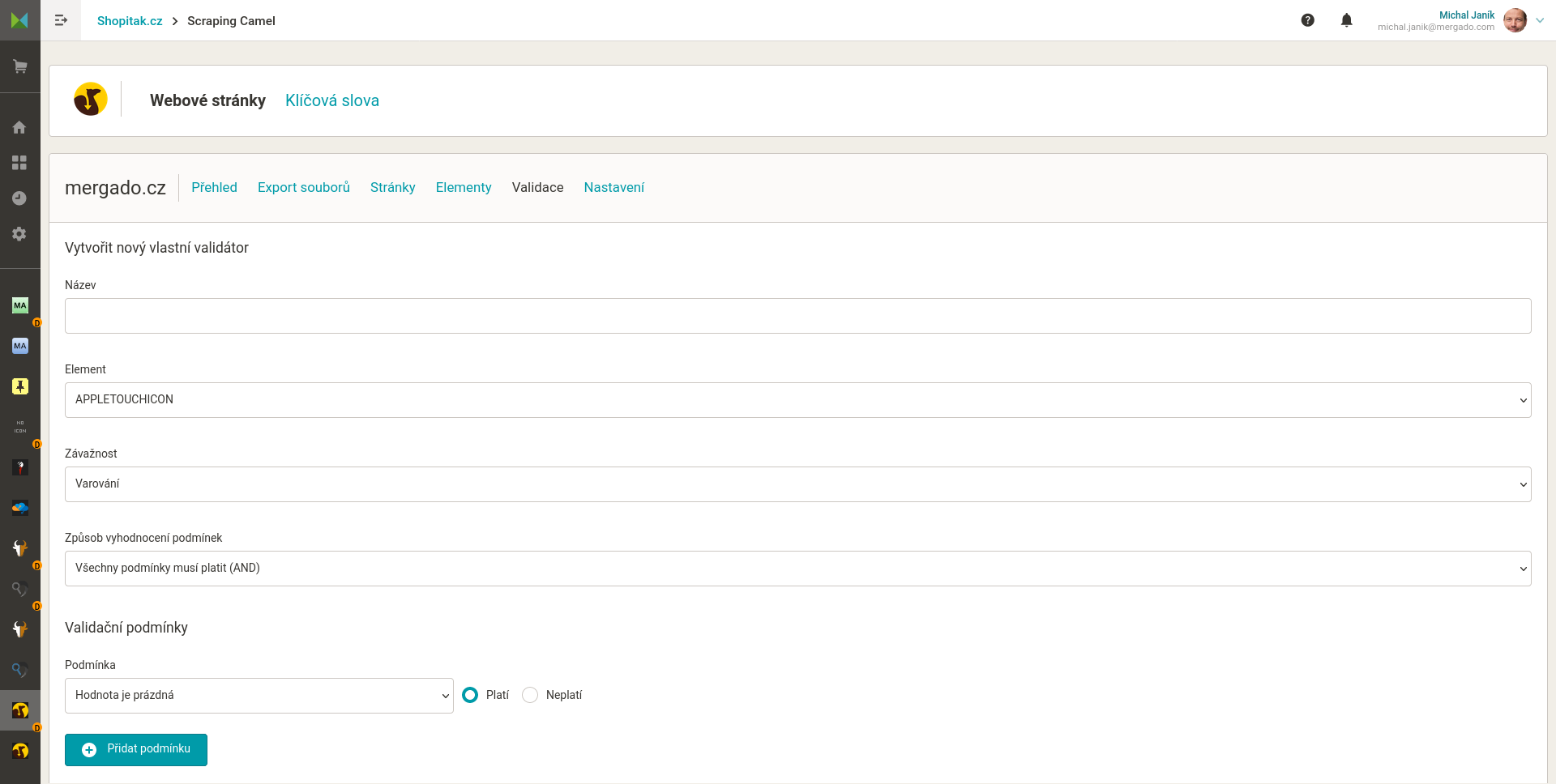
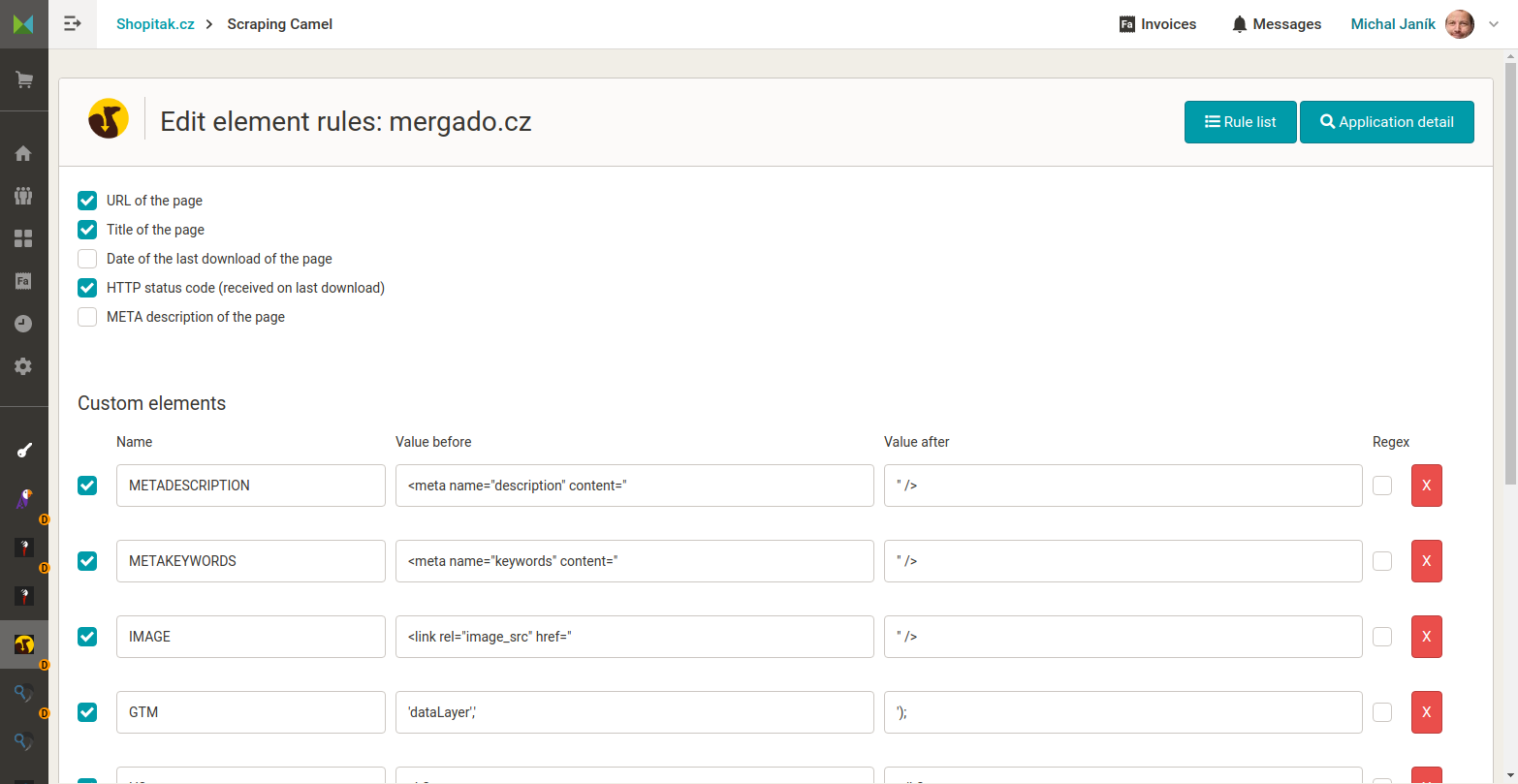
Nastavení dat, která má Camel z HTML stránek získat
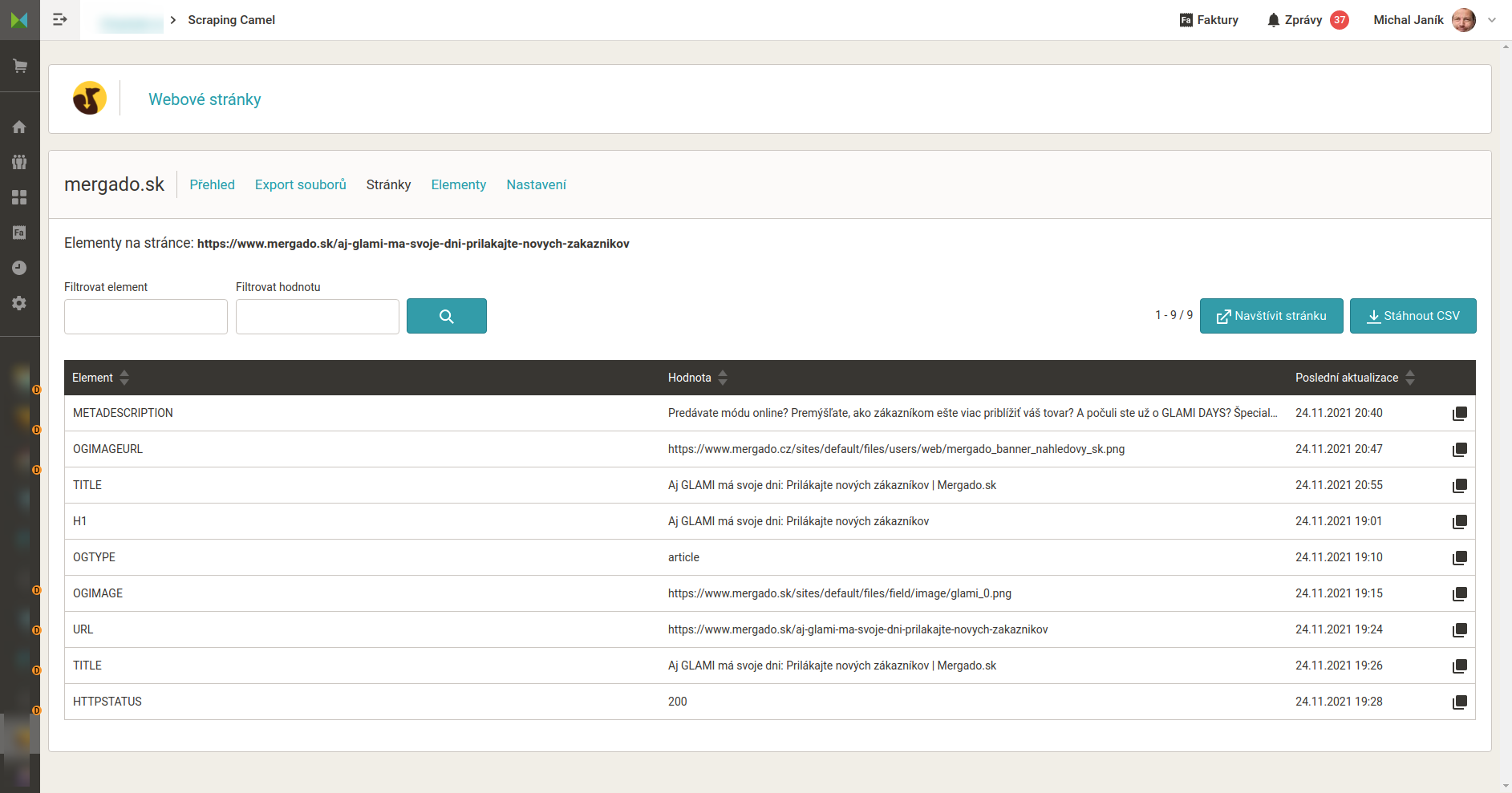
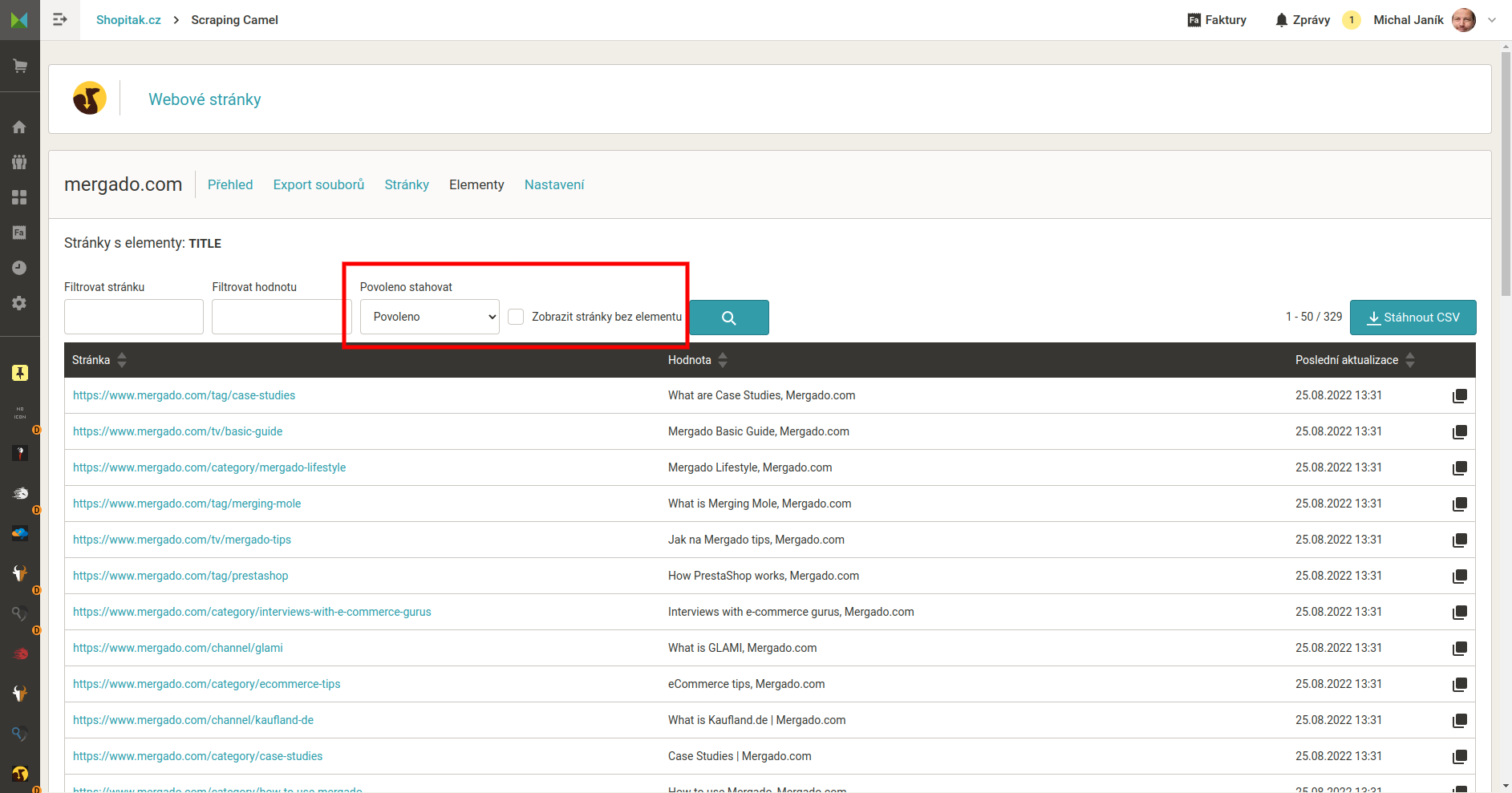
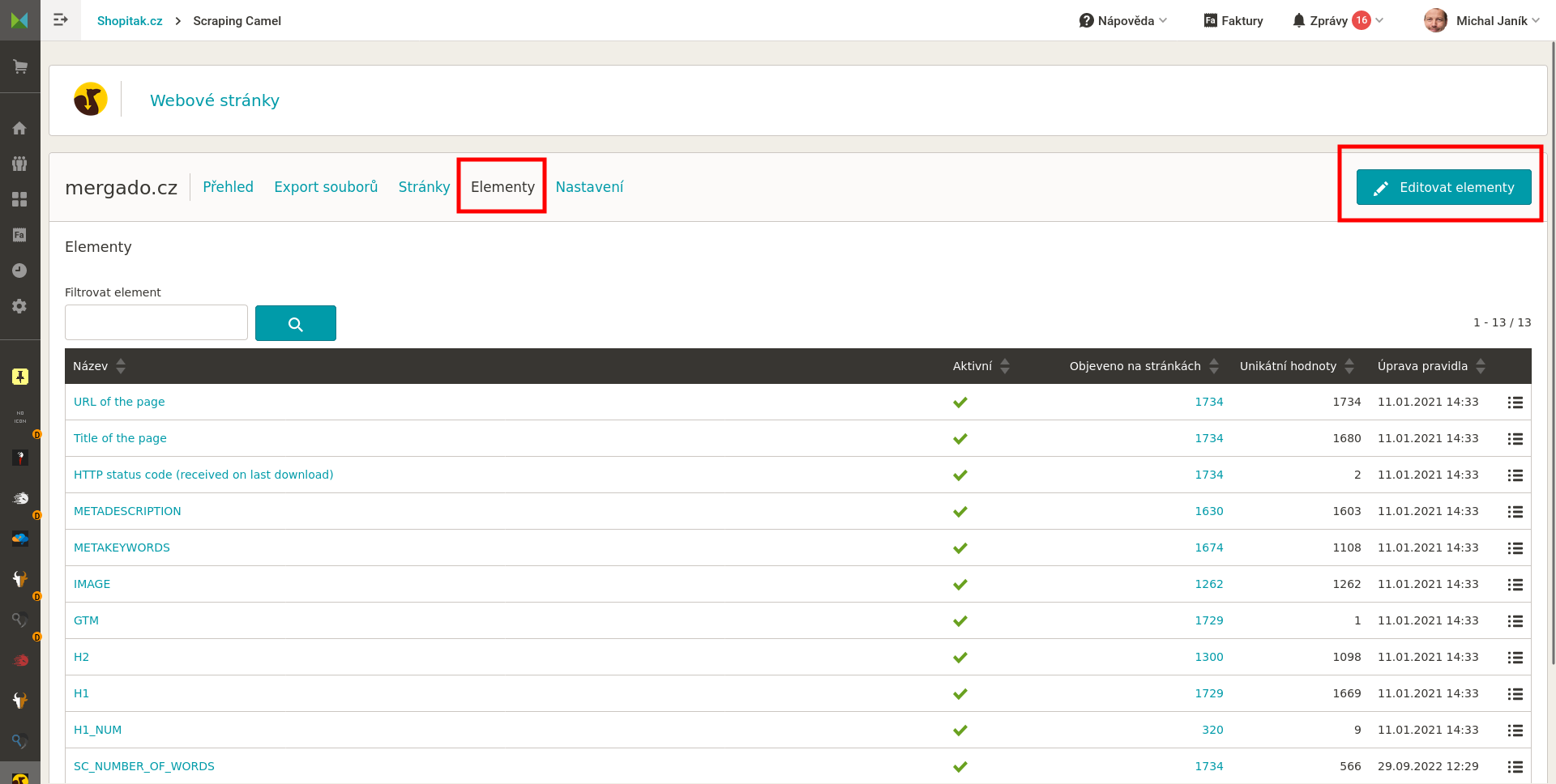
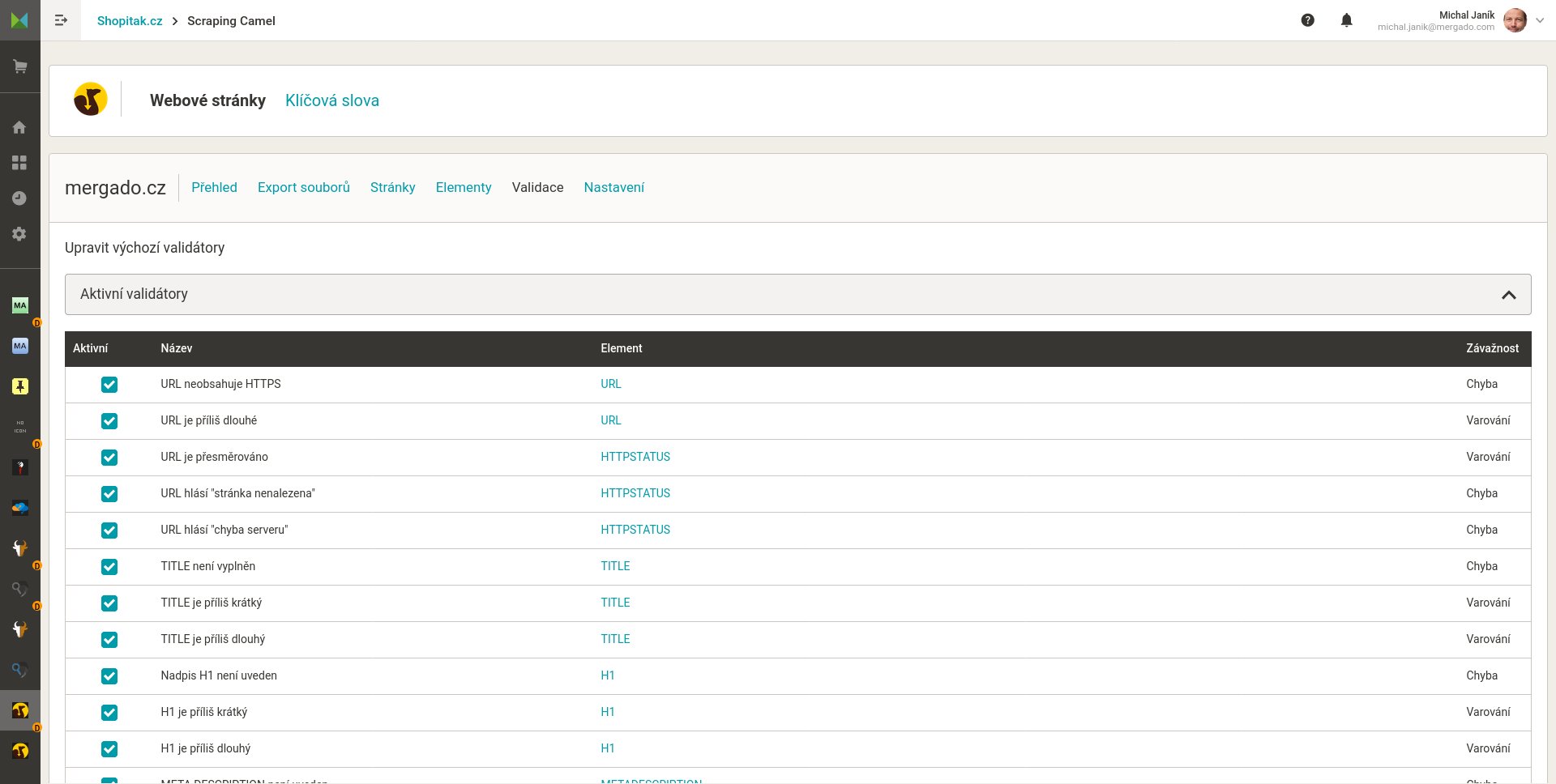
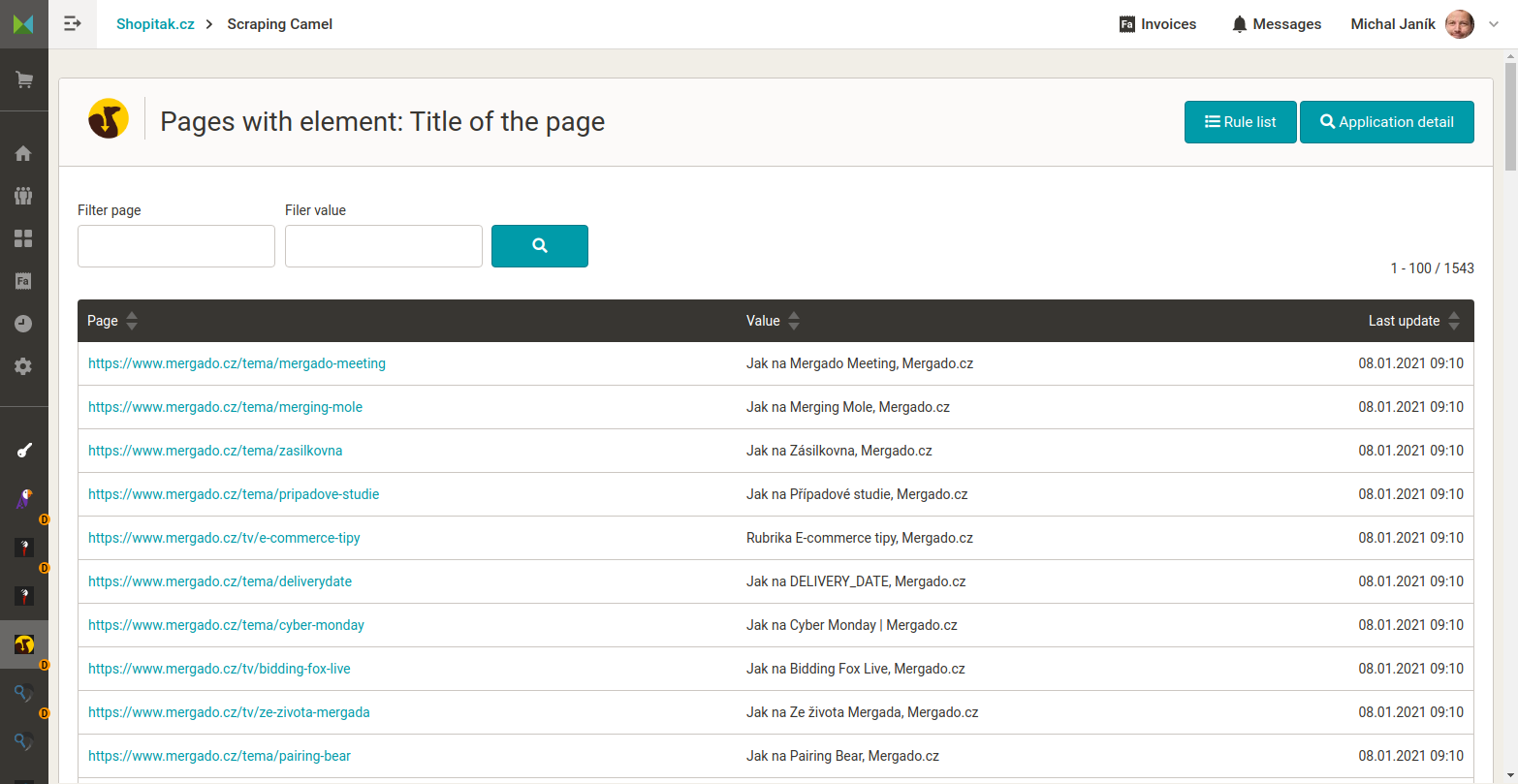
Seznam stránek které Camel zpracoval
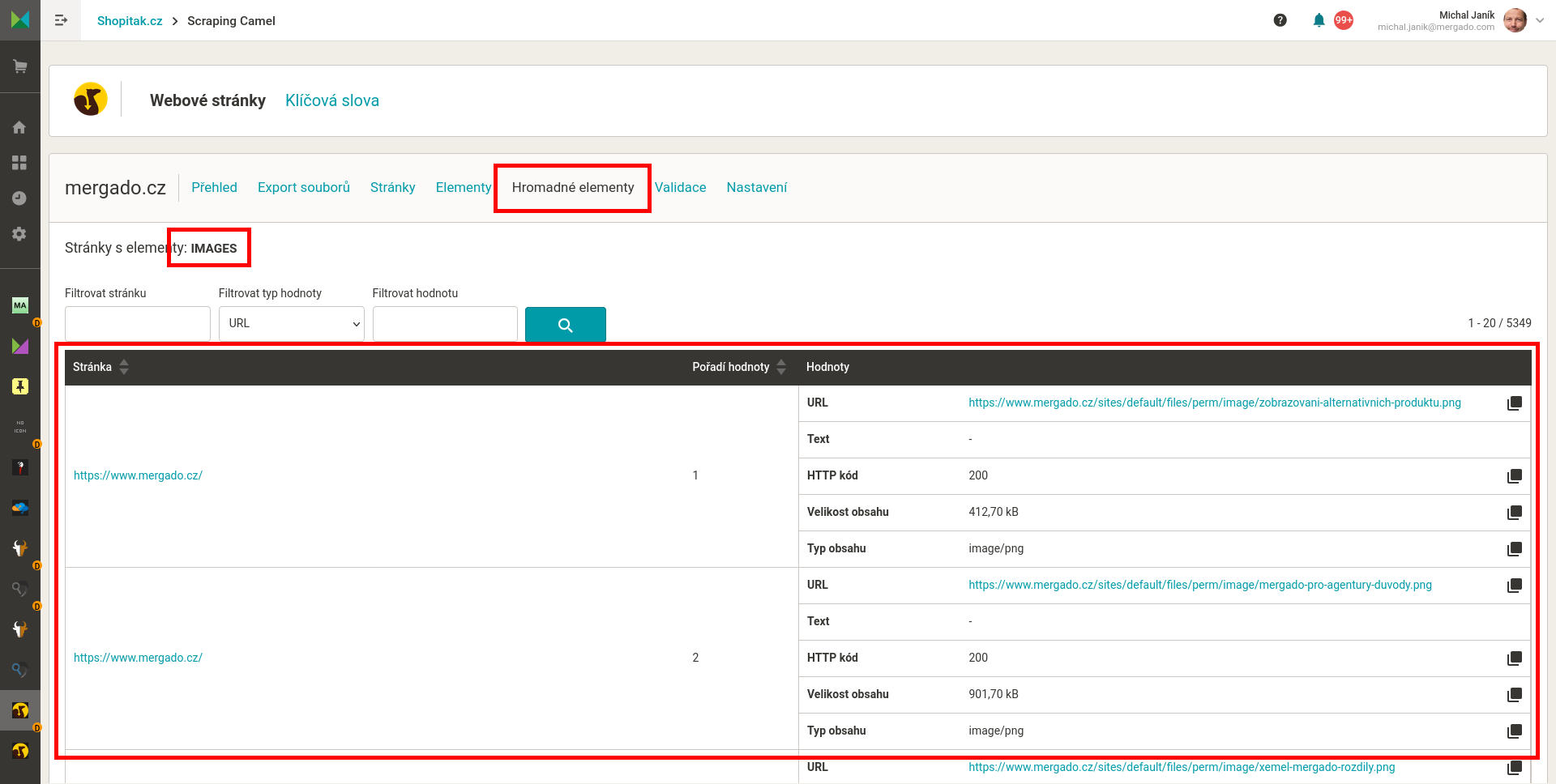
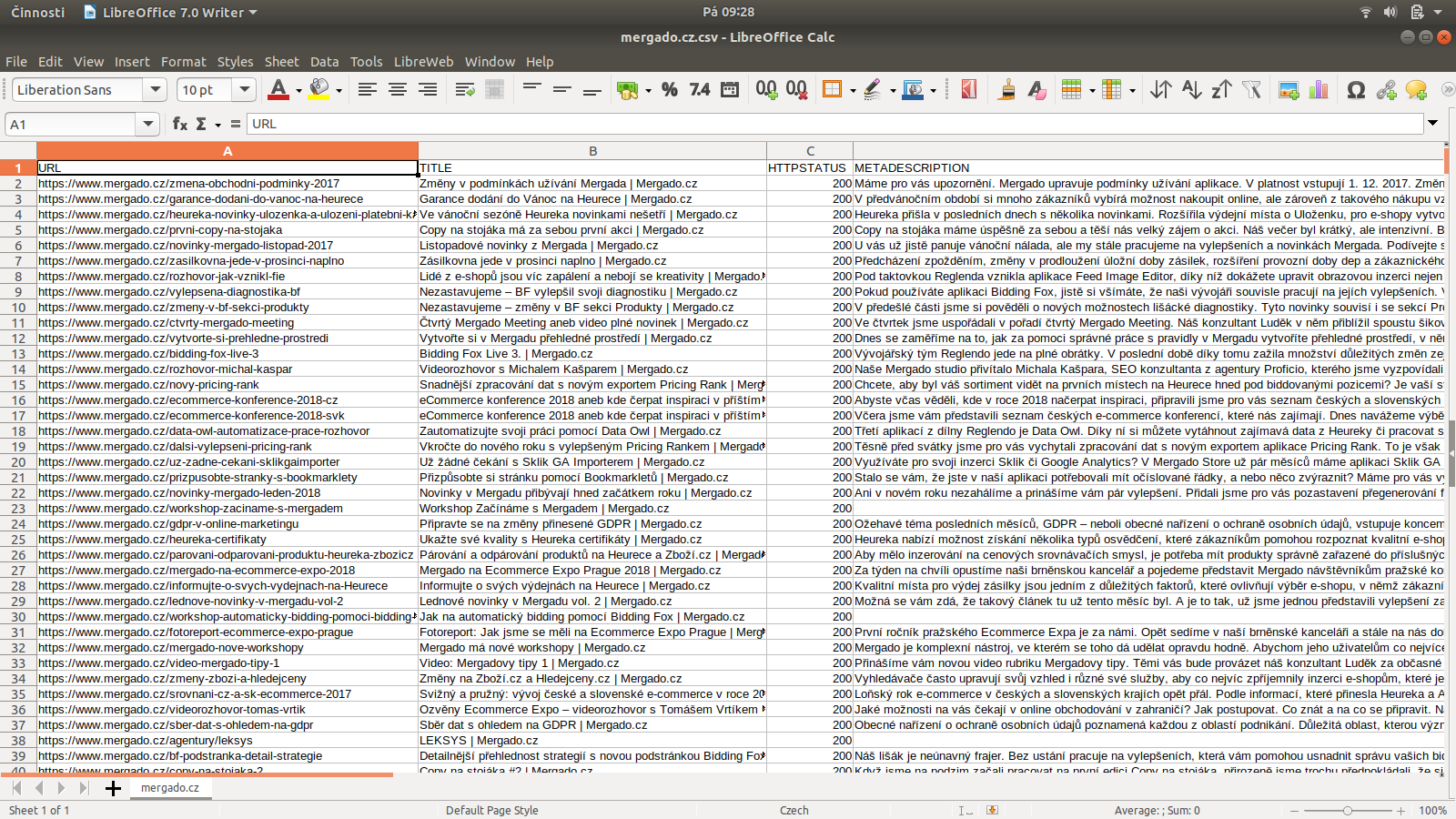
Příklad výstupních dat, je to CSV
Logo Scraping Camel

 Další informace & vyzkoušení
Další informace & vyzkoušení
Pro další informace a vyzkoušení aplikace pokračujte do Mergado Store.