Osobně stavím data-driven SEO na CSV feedu z aplikace Scraping Camel. Zpracuji jej v Mergado Editoru, přidám data z dalších zdrojů, např. Google Analytics, reportuji a dál využívám. Zde se podívám na to, jaká data získávám pomocí Scraping Camela z webových stránek.

Proč Scraping Camel
Podrobně si o Scraping Camelovi přečtete v odkazu na začátku stránky. Pro pochopení následujících řádek je podstatné, že cílem Scraping Camela je zpracovat web. Stáhnout stránky, vyparsovat z nich data a tato data vyexportovat do CSV feedu. Camel tedy prochází stránky webu a z nich data získává.
Jaká data získávat
Nejradši bych řekl úplně všechna, co jdou. V praxi ale musíme být rozumní. Doporučuji zakliknout elementy, které jsou ve Scraping Camelovi předdefinované, a při nastavení zpracování webu pro daný element najde data. Případně výskyt elementu očekáváte, jen se na dané stránce zrovna nevyskytuje. Nemusíte získávat data, která považujete za nepodstatná. Např. element GENERATOR obvykle zapotřebí pro data-driven SEO není.
Podstatné je, že data můžete projít v administraci Scraping Camela. Zkontrolujete je. A exportujete pro další zpracování pouze ta, která vám přijdou zajímavá. Jinými slovy, základní kontrolu můžete udělat v administraci Scraping Camela na stránce Elementy.
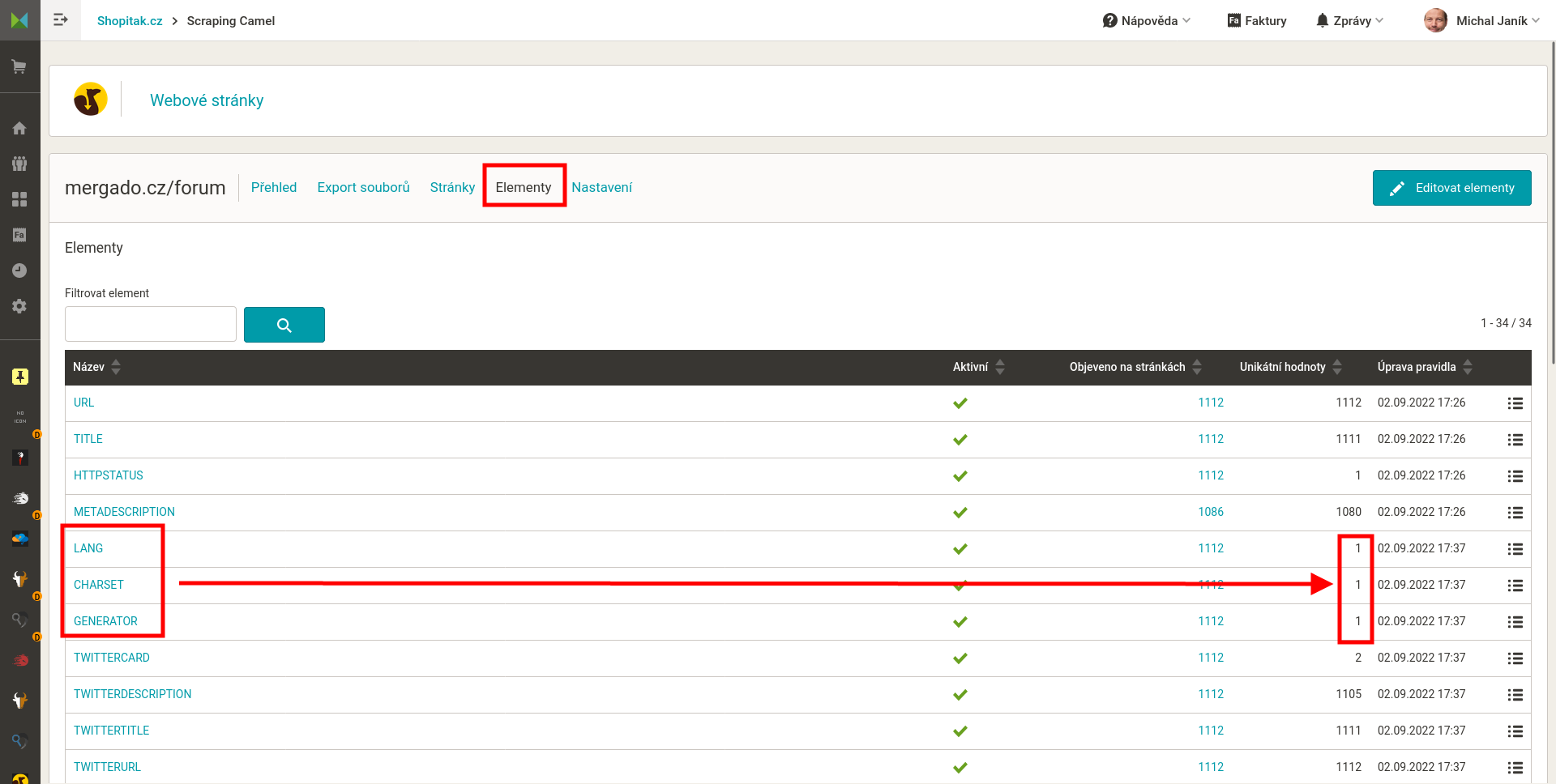
Příklad kontroly vidíte na obrázku výše. U elementů LNAG (jazyk stránky), CHARSET (znaková sada), GENERATOR (obvykle označení CMS) očekáváme jednu hodnotu. Z počtu hodnot vpravo je zřejmé, že tomu tak je. Elementy jsou málo významné. Do výstupného feedu bych je neexportoval.
Jaká data exportovat
Na stránce Export souborů vytvoříte a upravíte nastavení jednotlivých exportů.
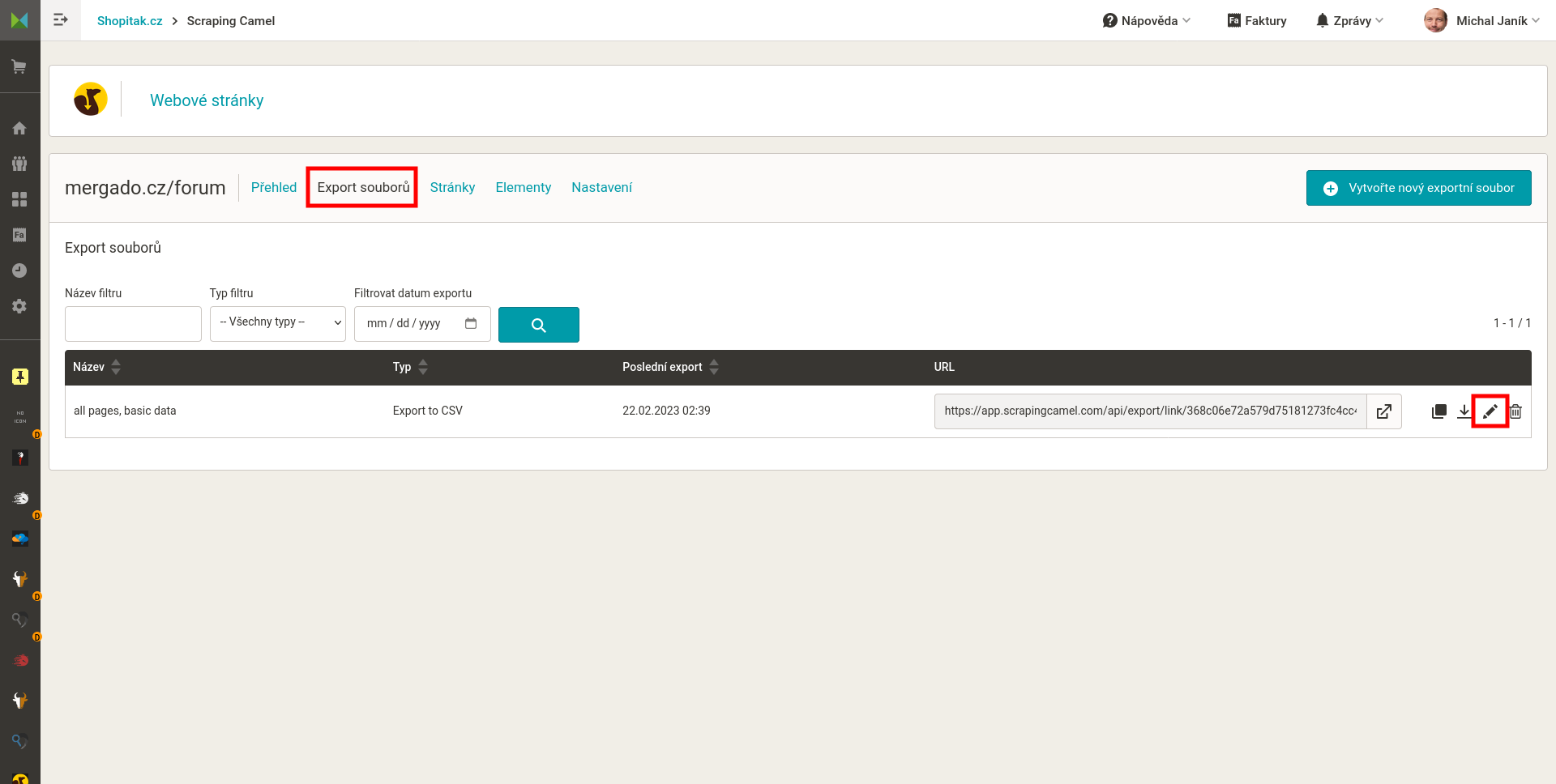
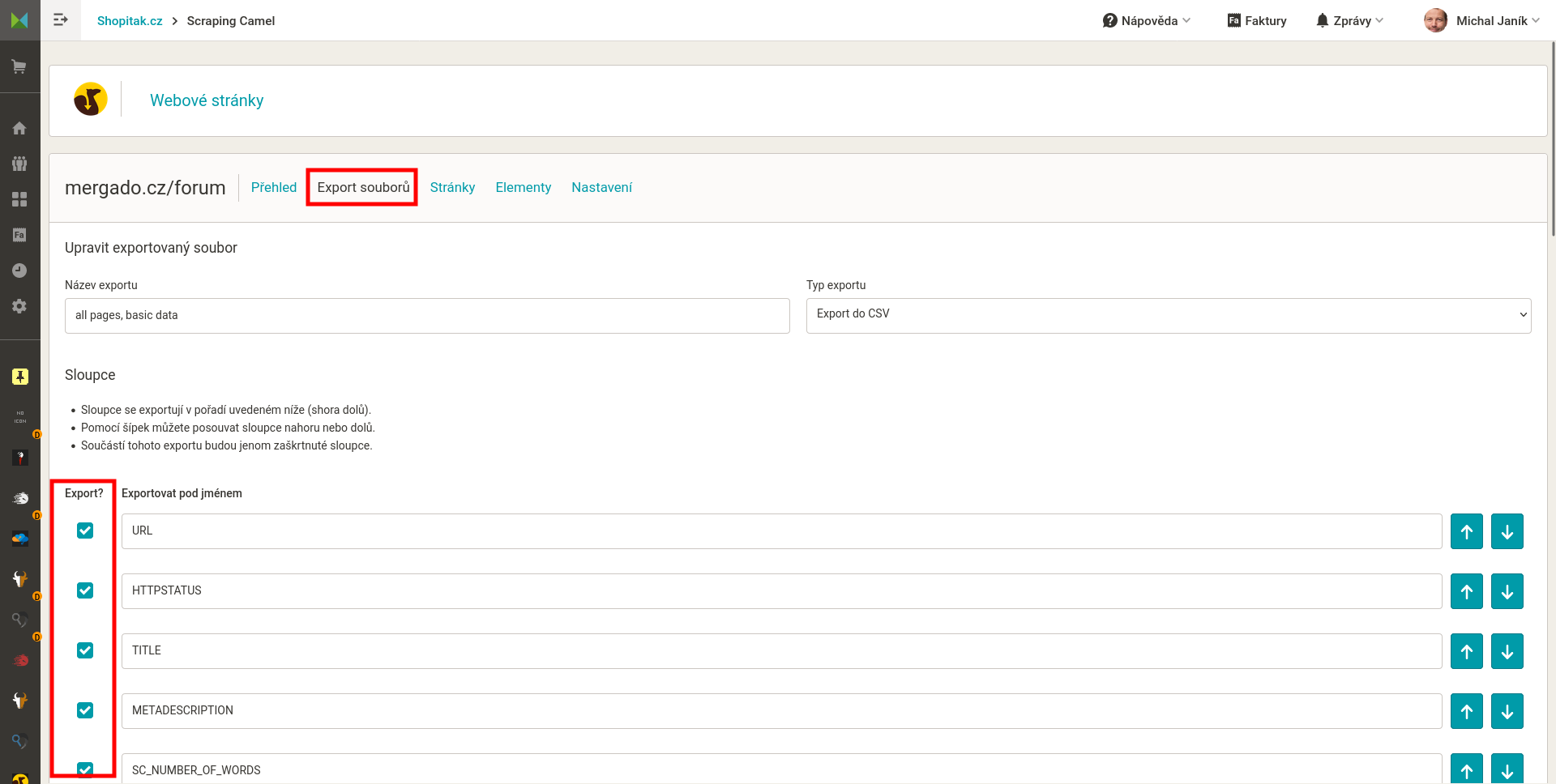
Uvedu příklady standardních elementů, které se mohou hodit. Platí, že konkrétní elementy přizpůsobíte aktuálním cílům a situaci.
Standardní elementy
- URL adresa stránky. Potřebná pro identifikaci stránky. Vhodná pro kontrolu, zda je validní atp.
- HTTPSTATUS stránky. 200 znamená, že je stránka nalezena. 3xx znamená přesměrování, 4xx chybu nenalezeno, 5xx chybu serveru atd.
- TITLE titulek stránky. Vhodný pro analýzu délky, nevhodných slov…
- METADESCRIPTION. Popisek stránky (nejen) pro vyhledávače, vhodný pro analýzu délky a obsahu.
- SC_NUMBER_OF_WORDS počet slov na stránce. Vhodný pro analýzu rozsahu stránky, detekci chybových stránek.
- H1 první nadpis.
- OGIMAGE microformát pro náhledový obrázek. Vhodný pro vyhledání stránek bez obrázku či s výchozím obrázkem, společným pro celý web.
- SC_WORDS_AGG_MIN_FREQ_3 klíčová slova dle Scraping Camel AI. Metod je více (SC_WORDS_COUNT, SC_WORDS_TUPLES_COUNT). Tuto doporučuji jako výchozí. Velmi cenné pro analýzu obsahu stránky.
- …další elementy podle uvážení a situace.
Uživatelem definované elementy
Můžete definovat vlastní elementy, do kterých bude Scraping Camel sbírat ze stránek data. Tyto bývají individuální a mohou být velmi cenné. Uvedu příklady:
- Kategorie stránky
- Štítky (tagy) článku, diskuse atp.
- Autor článku
- Počet komentářů, “lajknutí” článku
- U nápověd, zda stránka s otázkou obsahuje odpověď
- Drobečkovou navigaci
- …a další
K čemu data využijeme
Jak jsem zmínil, osobně takto vytvořený CSV feed nasadím do Mergado Editoru a nad ním vytvořím výběry a pravidla. Vhledem k tomu, že Scraping Camel generuje CSV feed dostupný na URL, můžete pro další zpracování použít i jiné nástroje.