Pište prosím nápady, co by se Vám líbilo, aby blending-bull uměl. Bude-li nápad obsahovat hlasování a Vám by se funkce hodila, klikněte do hlasování ať víme, jaké funkce tvořit dříve a jaké počkají.
Děkuji.
Pište prosím nápady, co by se Vám líbilo, aby blending-bull uměl. Bude-li nápad obsahovat hlasování a Vám by se funkce hodila, klikněte do hlasování ať víme, jaké funkce tvořit dříve a jaké počkají.
Děkuji.
Nápad č. 1
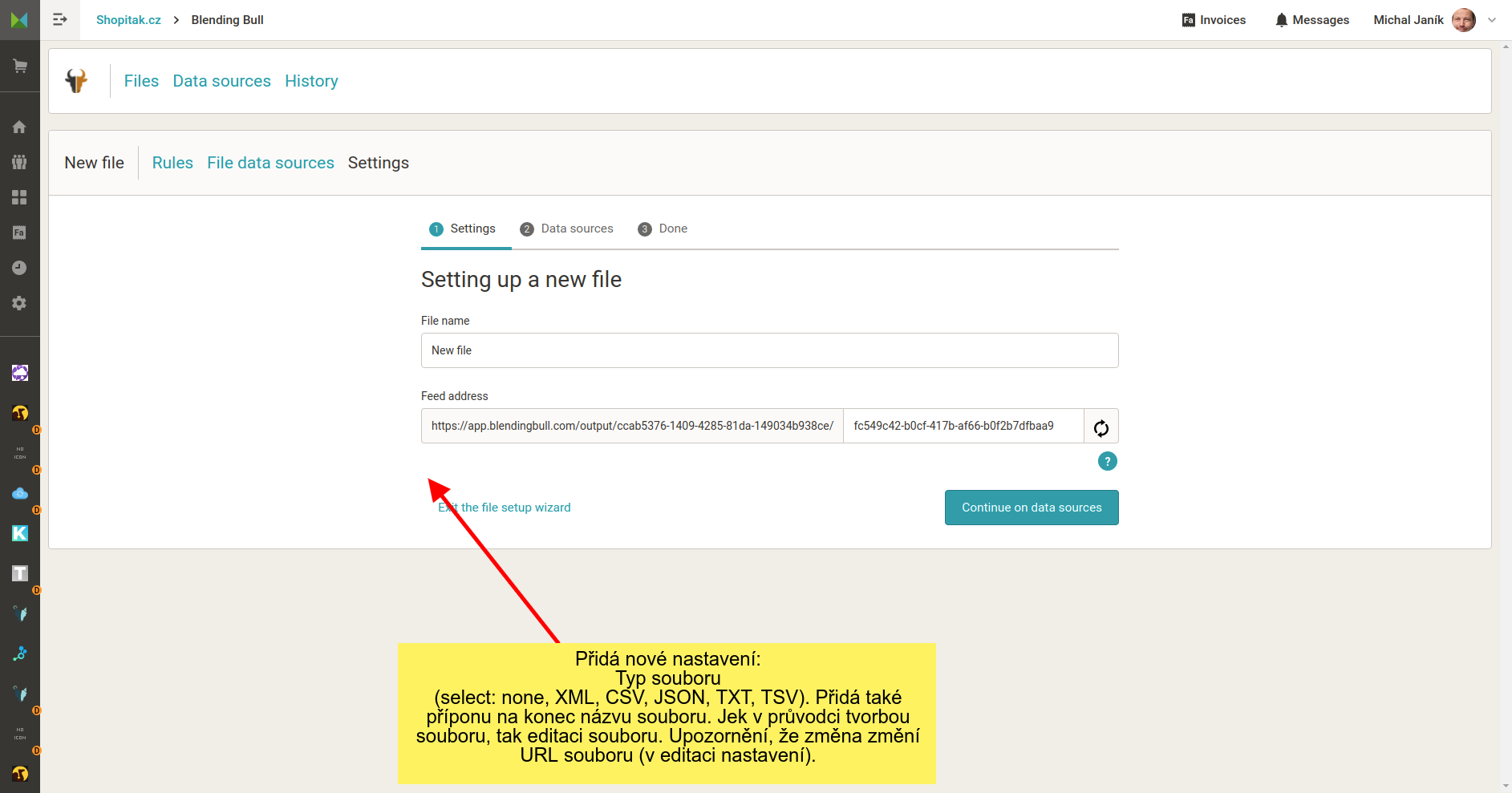
Nyní Blending Bull mime type nepodporuje. Příčinou bylo složité nasazení, resp. jsem nechtěl měnit URL souboru. Pro nasazení podpory mime type je přitom podstatné, aby soubor měl příponu. Např. nazevsouboru.xml aj.
Do průvodce tvorbou souboru a do nastavení doplnit volbu formátu souboru. vypadat by to mohlo viz náhled. V prvním kroku průvodce vytvořením souboru (a stránce nastavení) by byl select. Ten by nabízel možnosti: NEUVEDENO (výchozí možnost), XML, CSV, JSON, TXT, TSV. Výchozí by bylo neuvedeno a chovalo by se jako nyní. Pokud by uživatel vybral jinou variantu, na konec názvu souboru by se doplnila tečka a přípona. Např. .xml atp.
Pokud by nějaký cílový systém měl problémy bez korektního mime type soubor stahovat, toto by se vyřešilo.
Nápad č. 2
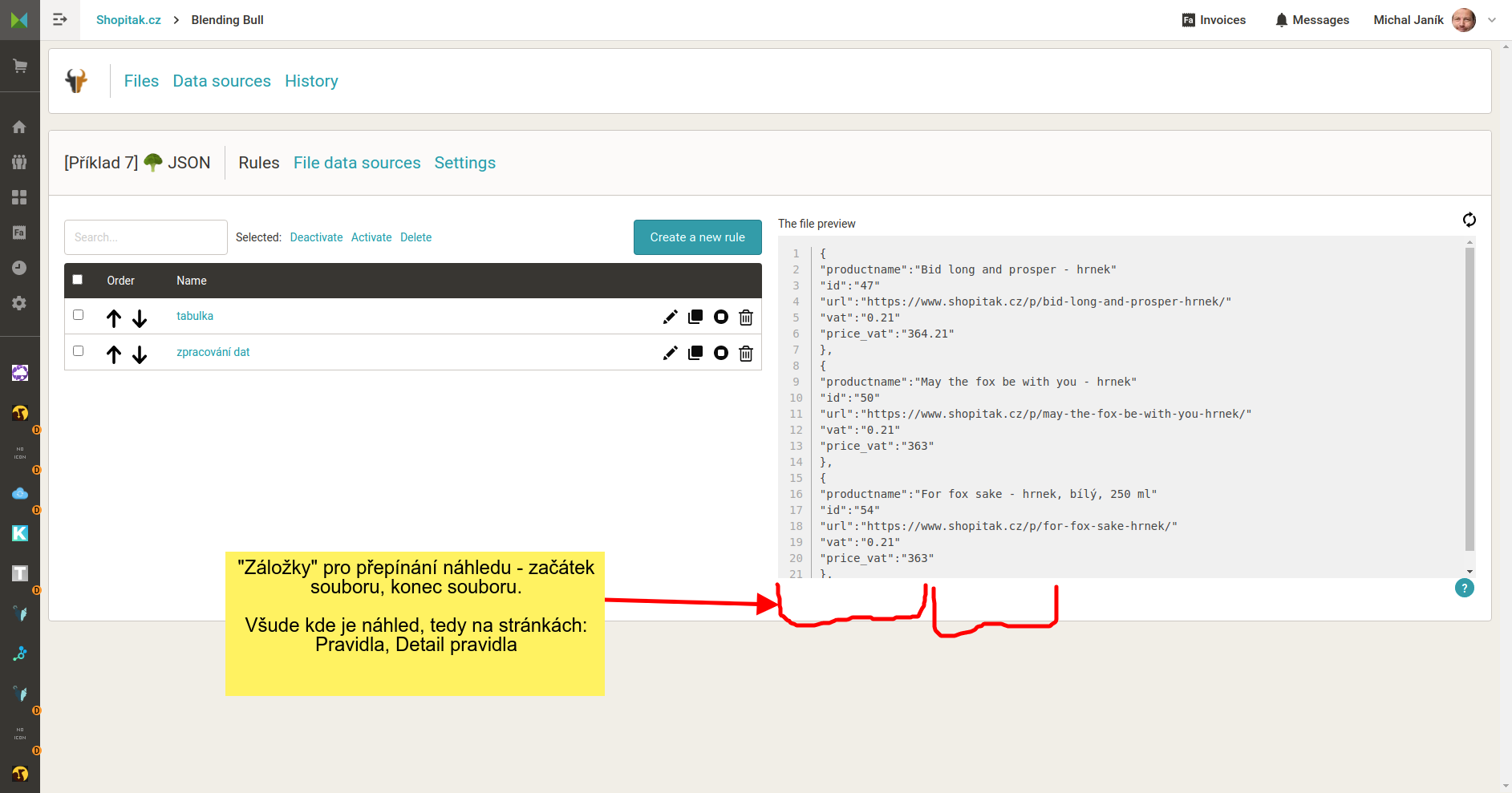
Uživatel edituje např. JSON. Chce si zkontrolovat, zda má na konci souboru správné znaky.
Např. do náhledu doplnit přepínač, který by přepnul, zda se zobrazuje začátek nebo konec souboru. Asi to bude technicky složitější - půjde o dva náhledy a nevím, jak pracné je náhled konce implementovat. Nicméně jako návrh toto vzít můžeme.
Možnost kontroly konce souboru.
Nápad č. 3
Nyní jsou všechny podstránky aplikace na společné URL viz př.: https://app.mergado.com/eshops/1235/applications/view/?app=blendingbull kde 12345 je ID e-shopu v Mergadu. Pokud tak pošlete odkaz např. e-mailem, zobrazí se vždy hlavní stránka Bulla.
Nasadit podporu vlastních URL. Mergado pro toto poskytuje speciální framework.
Nápad č. 4
Někdy je třeba opravit dostupnostní feed. Do něj vložit datum. To nyní neumíme.
Zavést “systémovou” proměnnou (proměnné) pro datum. Ta by vracela hodnotu ve tvaru např. 2021-12-31. Tedy dnešní datum. To by bylo fajn stanovit jednou, a pak v celém pravidle zapsat stejnou hodnotu. Případně pro více pravidel dohromady, pokud by to nebylo složité. Pozor totiž na zpracování dat kolem půlnoci, kdy se datum může během zpracování souboru změnit a hodnota by v jednom souboru mohla být různá.
Hodně sexy by bylo, kdyby uměl Bull s proměnnou datum počítat. Tedy něco jako “dnešní datum + 2 dny” by dne 31. 12. 2021 vracelo 2022-01-02. Je otázka, zda by to bylo programátorsky složité, případně jak stanovit syntax, aby byla pro uživatele srozumitelná.
Je otázka. jak systémové proměnné pojmenovávat. Mohli bychom zavést systém. Např. pojmenovávat velkými písmeny s BB_ na začátku. BB jako Blending Bull ![]() Alternativně by to mohlo být
Alternativně by to mohlo být BBULL_. Ale přijde mi to dlouhé. Mohly by tak vzniknout proměnné:
BB_DATE příklad: 2022-04-24BB_YEAR příklad: 2022BB_MONTH příklad: 04BB_DAY příklad: 24Do textu pravidla by se zapisovaly asi jako \<BB_DAY>. Tedy jako běžné proměnné, které si uživatel pojmenoval.
Nápad č. 5
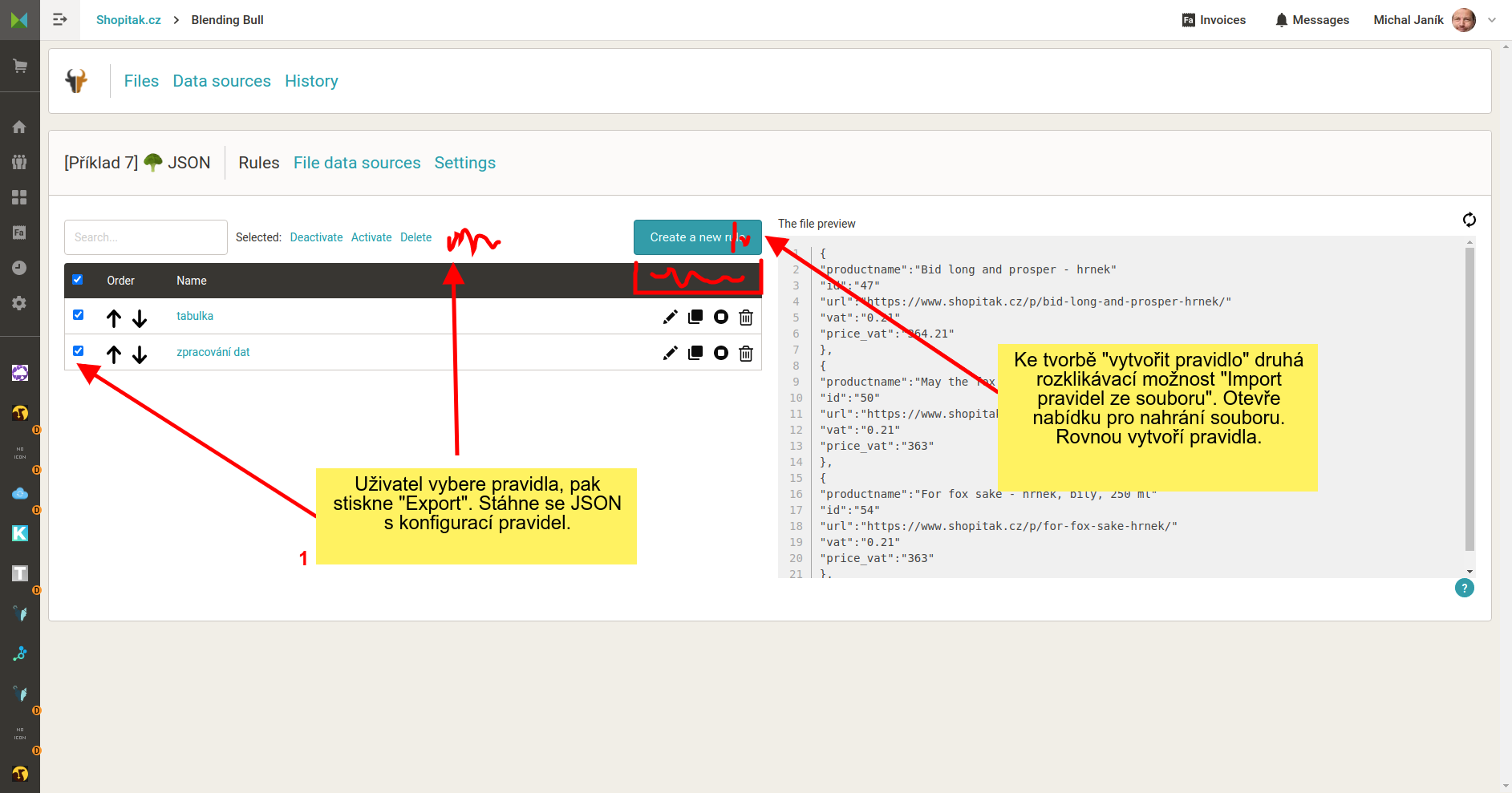
Uživatel dělá jedno nastavení vícekrát na různých souborech.
Umožnit uživateli export pravidel do souboru. To by mohl být např. zazipovaný JSON. Obsahoval by název a nastavení pravidel. Po nahrání by vytvořil pravidla. Ta by si následně uživatel upravil dle potřeby. Jinou část než pravidla bych neexportoval.
Např. uživatel konvertuje Heureka dostupnostní XML feed ja Mall dostupnostní. Nebo jiné opakované činnosti.
Nápad č. 6
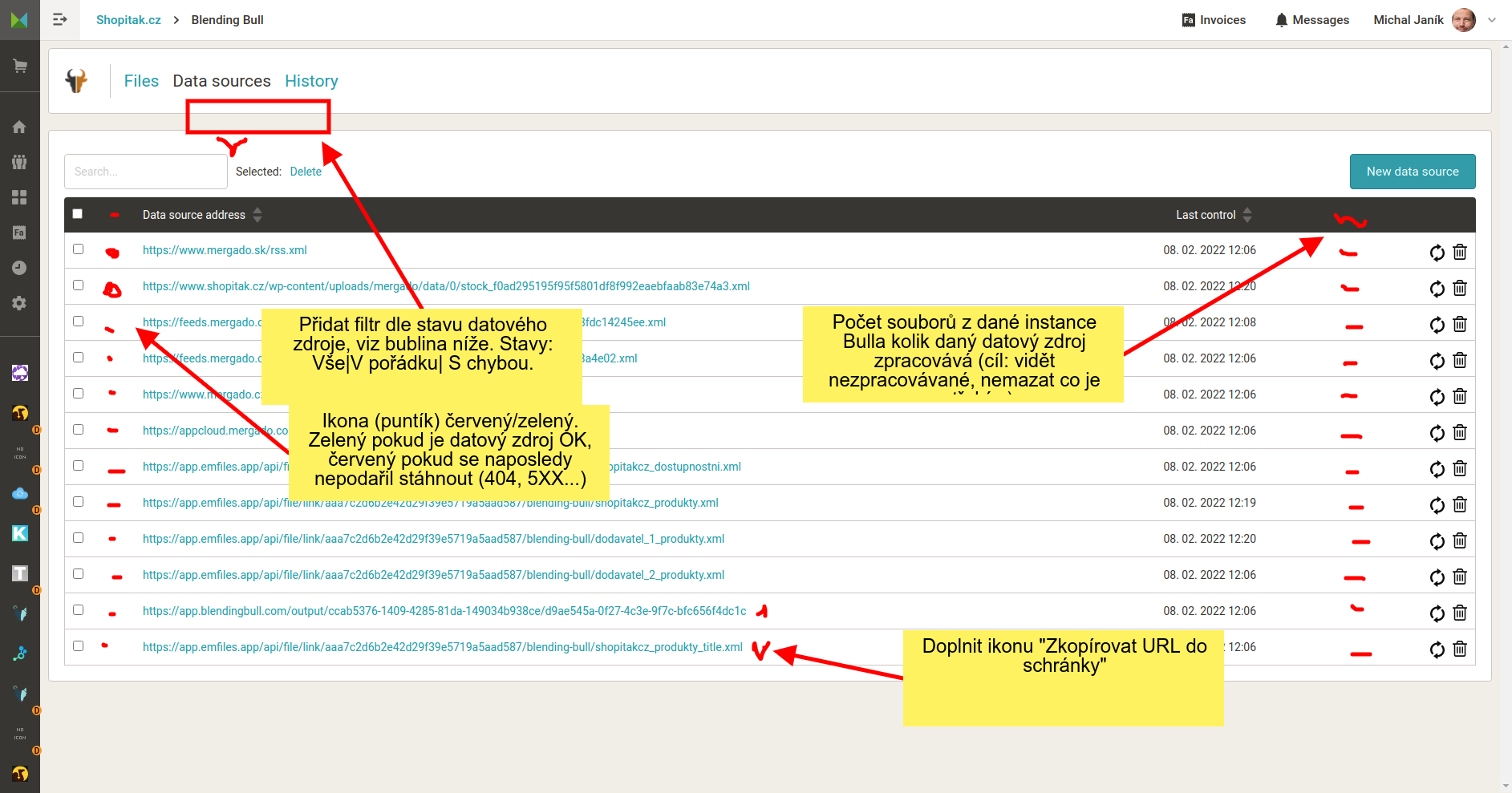
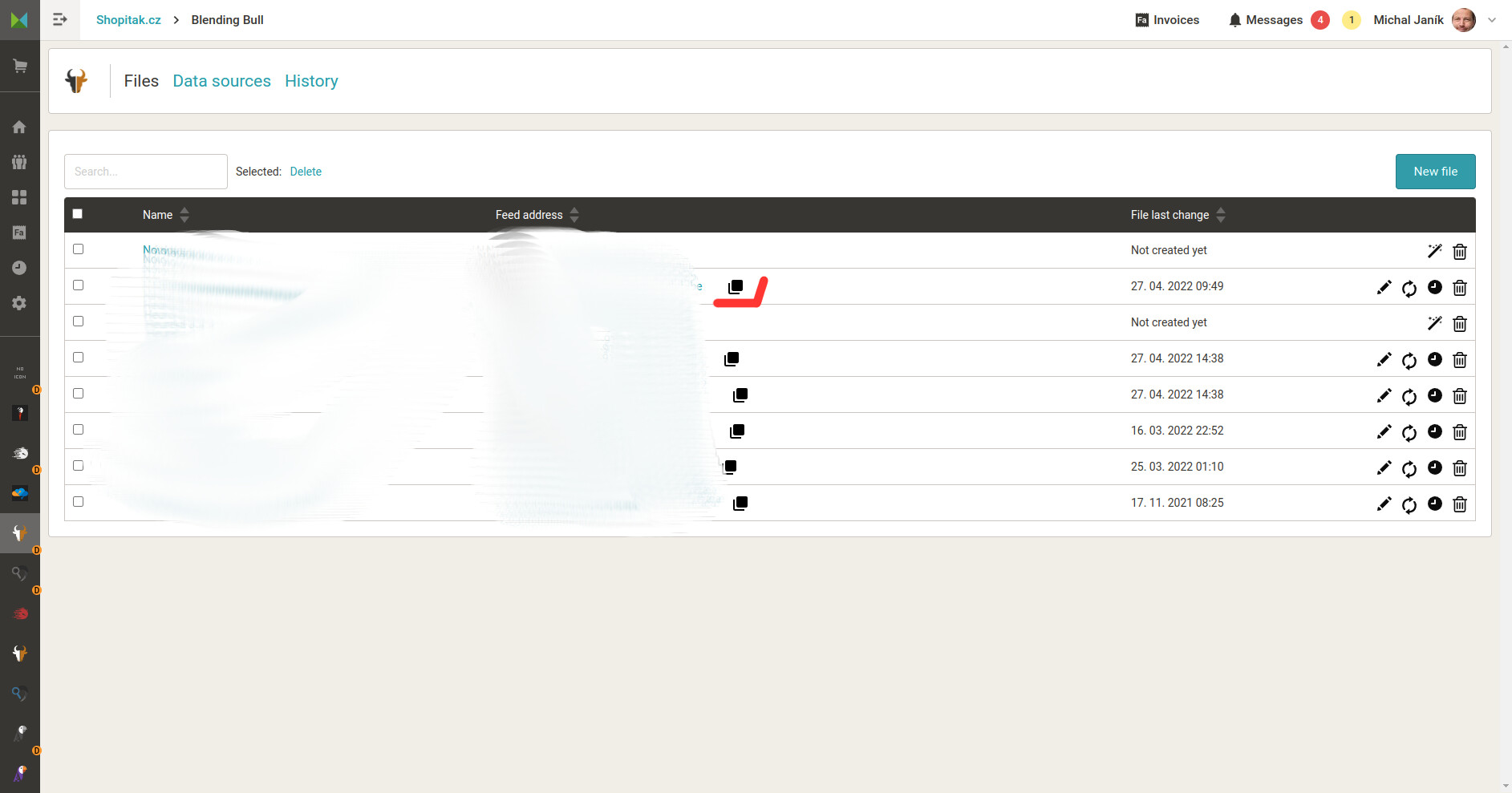
Viz náhled. Znamenalo by to k datovým zdrojům zavést ukládání jak dopadl pokus o stažení souboru. Zda zdrojový server vrátil http hlavičku 200 a soubor byl stažen, nebo zda došlo k chybě. Podle toho by se mohli i filtrovat. Dále by mohlo být fajn uživateli ukázat, zda konkrétní datový zdroj používá pro generování nějakého výstupního souboru. Zejména po delším čase se může stát, že výstupní soubor uživatel smaže, datové zdroje ponechá a ty Bull stahuje, i když nejsou potřeba.
@group_blendingbull prosím o pomoc. Přišly ke mě nápady na nové funkce Blending Bulla. K tomu jsem přidal některé nápady ze svého “notýsku”. A uvedl jsem je do příspěvků výše. Je otázka, zda nastal čas sestavit zadání na další verzi Bulla a pokud ano, co má prioritu.
Dáme tomu pár dní. Já pak hlasy spočtu. Když jich bude hodně, rozhodnu podle nic, které funkce Bulla naučíme a kdy.
Za pomoc moc děkuji.
@group_feedmarketing rád bych požádal o pomoc. V tomto vlákně jsem sepsal některé nápady na vylepšení blending-bull. Chtěl bych požádat o kliknutí hlasu funkcím, které vám přijdou cenné. Je možné, že podstatná není žádná. Ale kdyby byla, tak ať to víme a případně dodáme. Víc jsem se rozepisoval v komentáři výše.
Za pomoc děkuji.
Nápad č. 7
Volně navazuje na pravidla pro mazaní textů, bílých znaků, prázdných řádků…
Uživatel snadno odstraní celý řádek (např. jednu shopitem) s určitým textem (např. XML elementem určité hodnoty). Mám na mysli celý řádek, včetně řádkového zlomu na konci. Využití předpokládám např. společně po pravidlu “Zarovnat XML do tabulky”.
Vyřešit toto lze pomocí regulárního výrazu. Např. smazáním .*KONKRÉTNÍTEXT.*\n
Sestavit regulární výraz je pro některé uživatele obtížné. Toto pravidlo by situaci zjednodušilo. Předpokládám, že uživatel bude do pravidla zadávat text. Pokud by mohl vložit i regulární výraz, bylo by to bezva.
Nápad č. 9
Změna pořadí pravidel na méně kliknutí.
Jde o toto viz náhled níže. Pořadí pravidel se definuje kliknutím na ikonu šipky. Pokud je pravidel více, může být stanovení pracné. Mergado toto umožňuje tažením myší. Zdá se mi to méně pracné. Uživatel uchopí pravidlo za ikonu a posune. Po umístění do tabulky se nové pořadí uloží.
Nápad č. 10
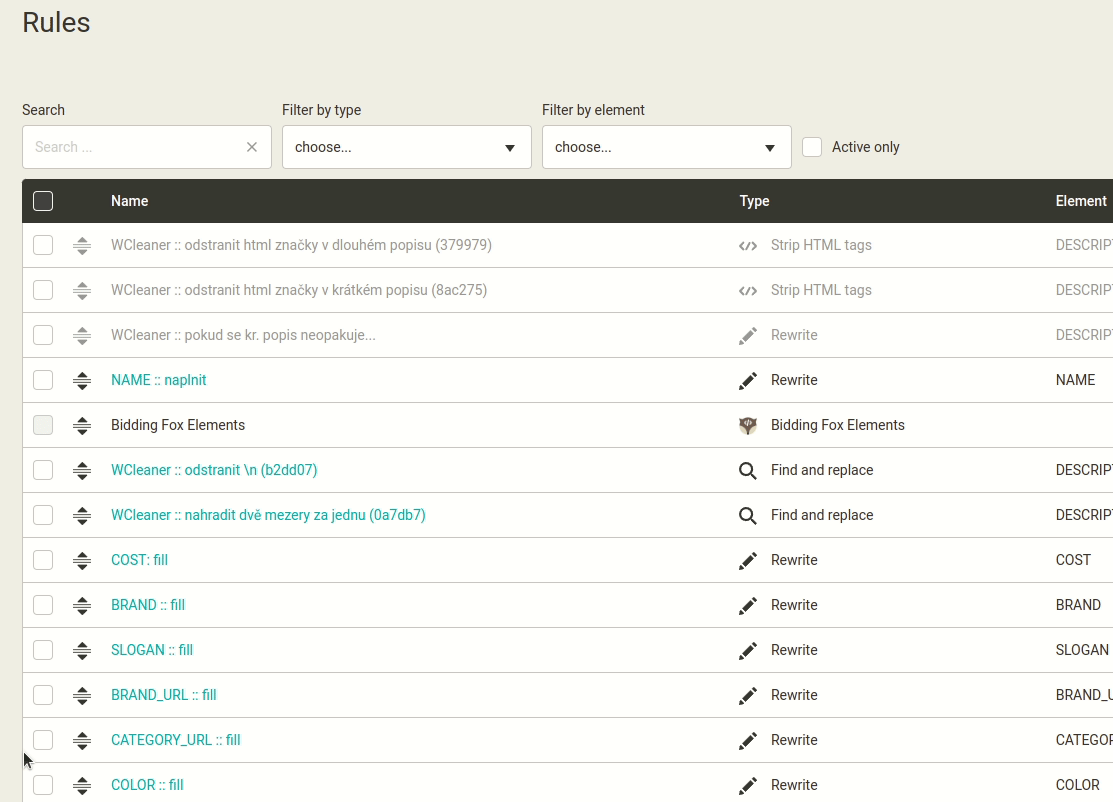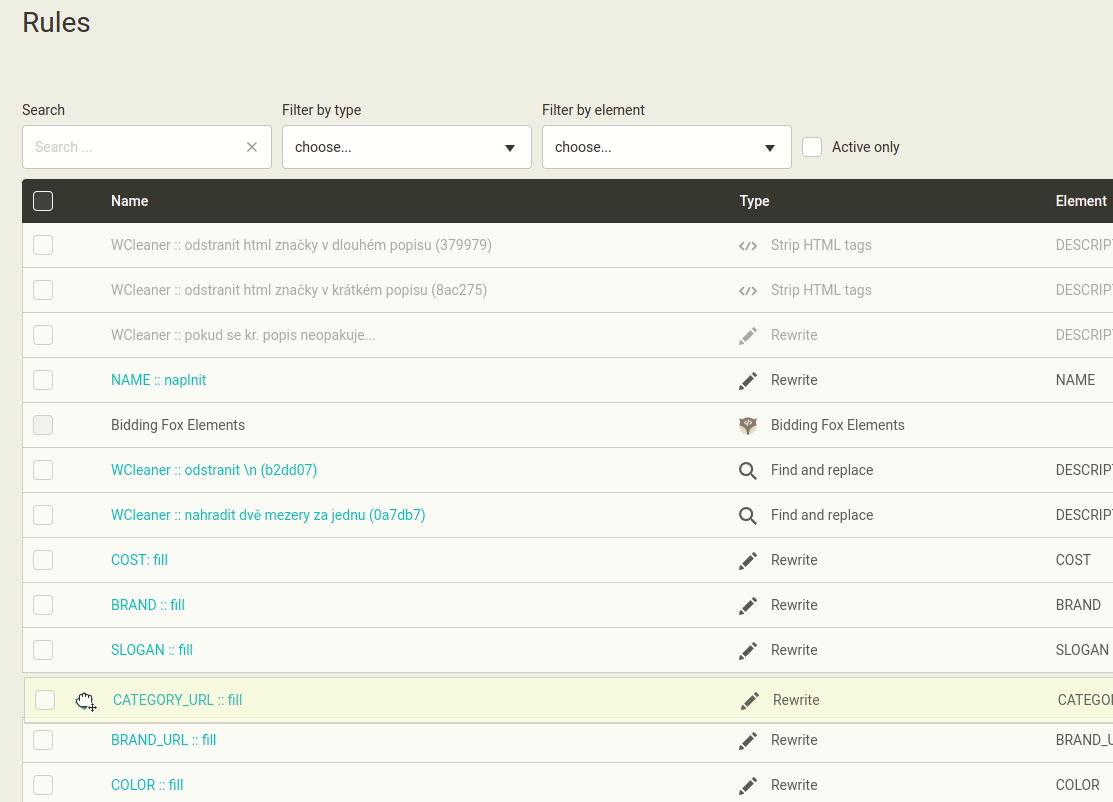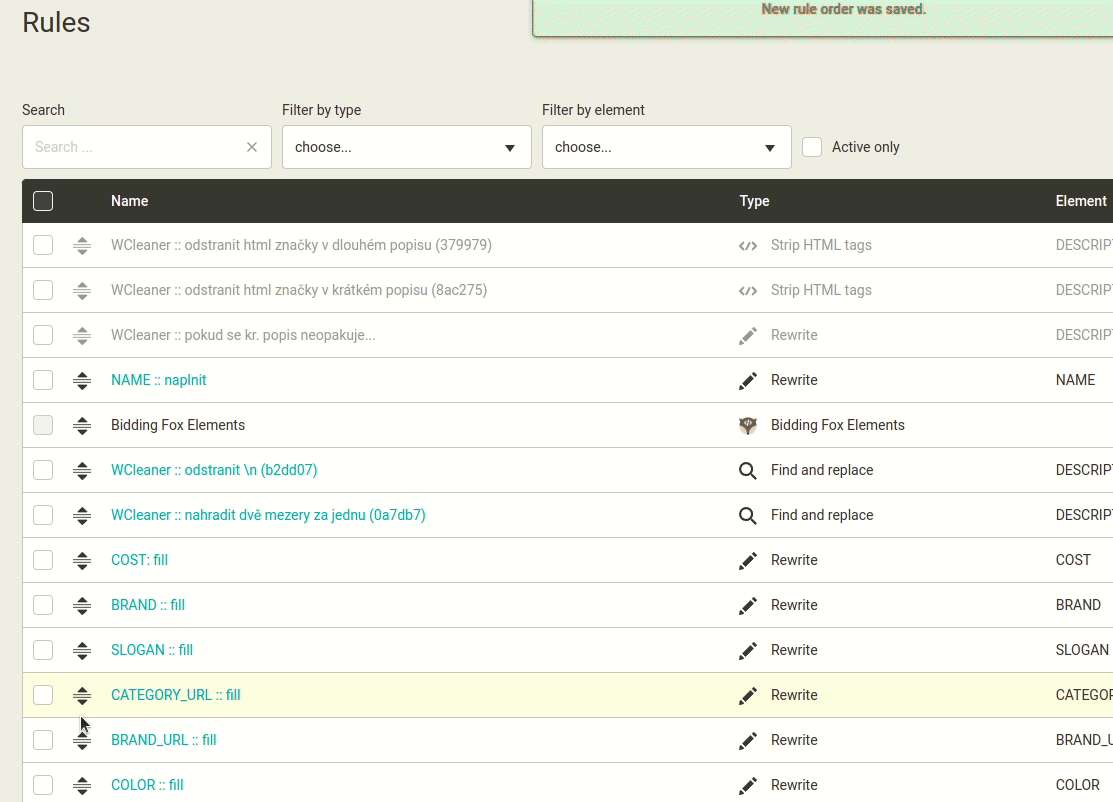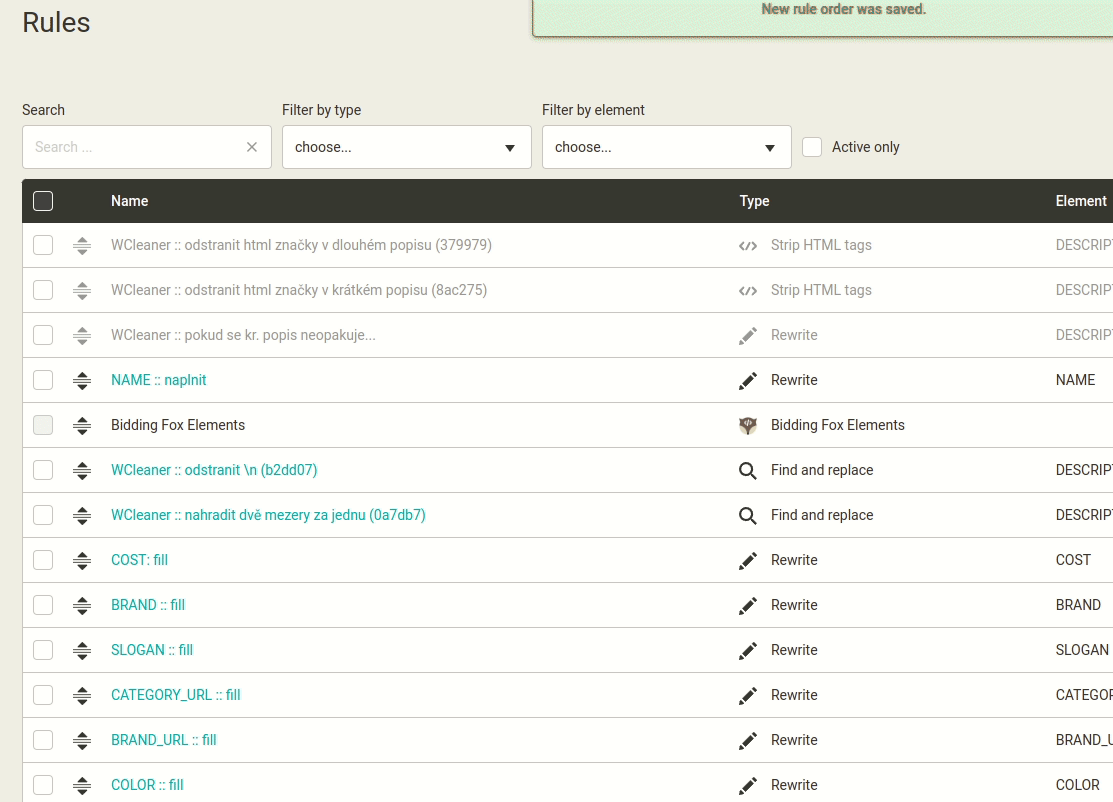
Na stránku Nastavení souboru navrhuji doplnit jednak ikonu pro zkopírování výstupní URL souboru, jednak doplnit možnost smazat soubor. Umístění viz náhledy. Ikona pro kopírování je de facto stejná jako na stránce Soubory. Umístil bych ji vlevo od ikony pro přegenerování nové URL. Dospod stránky bych dal nabídku “Smazat soubor”. To by mohlo být červené tlačítko. Po stisknutý by bylo nutno volbu potvrdit. Např. napsáním nějakého textu (např. DELETE). Po smazání by byl uživatel odeslán na stránku Soubory.
Nápad č. 11
Navazuje na pravidlo které smaže řádky obsahující text.
Uživatel chce z feedu odstranit všechny řádky, které např. neobsahují text <DELIVERY_DATE>0</DELIVERY_DATE>. A to včetně zalomení na konci řádku tak, aby nezůstaly po smazání v souboru prázdné řádky. Nyní to zapsat jde pomocí regulárního výrazu. Cílem je snazší zadávání.
Vyřešit toto lze (snad) pomocí regulárního výrazu.
Nápad č. 12
Řekněme, že jsem XML soubor s informacemi o zboží převedl v Bullovi pravidlem na “tabulku” tak, že na každém řádku je jedna položka zboží. Položky zboží obsahují označení výrobce. Např. <brand>Nike</brand> pro zboží značky “Nike”. Já bych potřeboval počítadlo. Toto počítadlo bude sledovat hodnoty v proměnné. Když najde hodnotu poprvé, zapíše do počítadla “1”. Když už hodnotu zná, navýší stav počítadla vždy o 1. Hodnotu počítadla může zapsat do souboru pomocí systémové proměnné.
Příklad vstupních dat:
<item><name>Tenisky A</name><brand>Nike</brand></item>
<item><name>Tenisky B</name><brand>Nike</brand></item>
<item><name>Tenisky C</name><brand>Adidas</brand></item>
<item><name>Tenisky D</name><brand>Botas</brand></item>
<item><name>Tenisky E</name><brand>Nike</brand></item>
Nyní zapnu počítadlo. jako proměnnou stanovím <brand>(.*)</brand>. Odtud budu čerpat hodnoty proměnné. Výstup zapíši do: <brand>\g<1></brand><counter>%BB_COUNT%</couter>[1]. Tedy do elemnu brand zapíši původní nalezenou hodnotu \g<1>. A za něj zapíši element counter do kterého zapíši proměnnou s hodnotou počítadla. Pro tento příklad jsem ji pojmenoval BB_COUNT. Pojmenování je pracovní. Jmenovat se může jinak. Výstup by pak vypadal takto:
<item><name>Tenisky A</name><brand>Nike</brand><counter>1</counter></item>
<item><name>Tenisky B</name><brand>Nike</brand><counter>2</counter></item>
<item><name>Tenisky C</name><brand>Adidas</brand><counter>1</counter></item>
<item><name>Tenisky D</name><brand>Botas</brand><counter>1</counter></item>
<item><name>Tenisky E</name><brand>Nike</brand><counter>3</counter></item>
Celkem by přitom počítadlo našlo proměnné:
| Hodnota proměnné | Počet |
|---|---|
| Nike | 3 |
| Adidas | 1 |
| Botas | 1 |
Z příkladu je vidět, že u nalezených výskytů obsahu proměnné, se hodnota počítadla postupně navyšuje. Tak jak pravidlo prochází data. Pokud bych ze vstupního příkladu vyfiltroval pouze řádky, kde proměnná \g<1> nabývá hodnoty Nike, vypadaly by tyto řádky po zpracování pravidlem s počítadlem následovně:
<item><name>Tenisky A</name><brand>Nike</brand><counter>1</counter></item>
<item><name>Tenisky B</name><brand>Nike</brand><counter>2</counter></item>
<item><name>Tenisky E</name><brand>Nike</brand><counter>3</counter></item>
Zde je vidě, že hodnota počítadla postupně roste: 1 - 2- 3…
Jiné aplikace zpracování dat paralelizují. Je tedy komplikované v práci zohlednit vztahy mezi shopitems. Např. zda je zboží daného názvu v nabídce unikátní, zda se název zboží opakuje (má varianty, kolik těch variant je atp.) atp. Bull pracuje lineárně. Toho bychom mohli využít a práci s vícenásobnými výskyty zavést.
Nastíním laicky. Mohlo by jít o speciální typ pravidla. Něco jako “Najít a nahradit s počítadlem”. Nebo by se počítadlo volitelně mohlo zapnout u stávajícího pravidla Najít a nahradit. Pravidlo by v textu hledalo text který splní zadání uživatele a z něj vyparsuje proměnnou. Novinkou by byl “dočasný zásobník”. Do něj by pravidlo nalezené hodnoty “házelo”. Vždy zkontrolovalo zda tam hodnota už je. Pokud není, zapíše nově. Pokud je, číslo počítadla navýší o jedničku. Po ukončení práce pravidla by se zásobník vyprázdnil. Hodnota počítadla pro danou proměnnou by byla uživateli přístupná v (nějaké) systémové proměnné. Podobně jako např. datum.
Viz výše, napadají mne dvě možnosti:
Syntaxi zápisu proměnné jsem převzal z proměnné datum. ↩︎
Nápady č. 1, 3, 4, 6, 7, 9 a 10 byly zrealizovány ve verzi 5. V seznamu výše jsem je označil zaškrtnutým checkboxem a barevně. Nápady nepodbarvené nevzbudily (zatím) takový zájem, abychom je realizovali.
Případné další nápady prosím pište. Nebo posílejte na support.
Děkuji.
Nápad č. 13
Svým způsobem protiklad stávajícího pravidla Smazat XML značku i s obsahem
Uživatel chce v souboru ponechat pouze jedinou XML značku i s hodnotami. Nyní toto může řešit regulárním výrazem. Nově by se mu zadávání zjednodušilo. Využije např. při generování produktových skupin z názvů produktů.
Vstupní data:
<SHOPITEM>
<ITEM_ID>123</ITEM_ID>
<PRODUCTNAME>Velký poklad</PRODUCTNAME>
<DESCRIPTION>Lorem ipsum. Možná i s HTML...</DESCRIPTION>
<URL>https://www.blendingbull.com/velky-poklad/</URL>
<PARAM>
<PARAM_NAME>Barva</PARAM_NAME>
<VAL>červená</VAL>
</SHOPITEM>
<SHOPITEM>
<ITEM_ID>456</ITEM_ID>
<PRODUCTNAME>Ještě větší poklad</PRODUCTNAME>
<DESCRIPTION>Lorem ipsum. Možná i s HTML...</DESCRIPTION>
<URL>https://www.blendingbull.com/vetsi-poklad/</URL>
<PARAM>
<PARAM_NAME>Barva</PARAM_NAME>
<VAL>zelená</VAL>
</SHOPITEM>
Uživatel zadá pravidlo Smazat všechny XML značky kromě uvedené s parametrem PRODUCTNAME.
Výstup:
<PRODUCTNAME>Velký poklad</PRODUCTNAME>
<PRODUCTNAME>Ještě větší poklad</PRODUCTNAME>
Nápad č. 14
Uživatel čistí seznam klíčových slov. Na každém řádku má několik slov. Na výstupu chce ponechat pouze řádky, které mají např. méně nebo rovno 30 znaků.
Laicky bych to napsal regulárním výrazem. Mazal bych např. .{30,}. Odborník by to asi navrhl lépe. Toto je příklad. Podle mne by pravidlo mohlo mít dvě vstupní políčka:
< = > (select)Nápad č. 15
Uživatel čistí seznam klíčových slov. V něm jsou např. číselná ID položek zboží. Ta chce smazat všechna. Neumí ale napsat regulární výraz. Pravidlo mu v tomto pomůže.
Pravidlo. Uživatel kliknutím vybere skupinu, kterou chce smazat. Mohly by to být checkboxy a uživatel mohl vybrat více položek v jednom pravidle. Mazání by mohly obstarat regulární výrazy. Uvedu příklady.
[0-9]* nebo \d*[A-Z]*[a-z]*\W(\w{.....,.....})\W kde místo teček je číslo)Blending Bull nyní obsahuje pravidlo Smazat všechny bílé znaky v souboru". Toto pravidlo jej de facto rozšiřuje. Mohlo by ho tedy nahradit.
Je k zamyšlení, zda toto pravidlo nespojit i s pravidly Smazat bílé znaky na začátcích řádků a Smazat konce řádků.
Nápad č. 16
Pokud uživatel z textu smaže některá slova, mohou zůstat mezery co byly např. před a za slovem. Tím pádem bude v textu více mezer po sobě. Příklad: Dámské hodinky typ 123 bílé po odstranění slov typ a 123 zůstane: Dámské hodinky bílé. Mezi slovy hodinky a bílé budou tři mezery. Cílem je, aby zůstala mezera jediná.
Toto půjde zapsat regulárním výrazem. Např. mezera{2,} nahradit za mezeru jedinou.